Why this matters now. Reliance on large cloud-hosted models is a single point of failure: API quotas change, prices rise, services go down, regions get restricted. If your agent workflow depends entirely on a remote API, you are one step away from a full stop. Testing local models is not a hobby — it is operational resilience.
On top of that, Ollama has just shipped a release specifically optimized for the Apple M4/M5 Neural Engine and unified memory architecture. The performance gap between local and cloud inference is shrinking fast — and we need hard numbers to know exactly where it stands today.
Every model writes working code. Every model passes tests. But when you plug them into Claude Code as an agent backend — 4 out of 6 break. One model diagnoses its own bug but can’t fix it. Another ignores the task entirely and starts configuring your memory system. A third invents tools that don’t exist.
Only 1 out of 6 is actually usable for daily work.
I tested 6 local LLMs via Ollama 0.20.2 on a MacBook Pro M4 Max with 48GB. One task, identical prompt, two modes: direct generation via API and Claude Code CLI agent backend. The results demolish the “bigger model = better agent” myth.
Setup: MacBook Pro M4 Max, 48GB Unified Memory. Ollama v0.20.2, Claude Code CLI v2.1.85. All models Q4_K_M quantization. Settings: num_ctx=32768, temperature=0, max_tokens=8192.
The task: Write a thread-safe LRU cache in Python using OrderedDict and threading.Lock, with type hints, docstrings, and 5 pytest tests. Same prompt for all models and both modes.
The 6 models:
| Model | Architecture | Total / Active Params | VRAM |
|---|---|---|---|
| gemma4:latest | Dense | 8B | 11.6 GB |
| gemma4:26b | MoE | 25.2B / 3.8B active | 21.4 GB |
| gemma4:31b | Dense | 30.7B | 29.8 GB |
| qwen3-coder:30b | Dense | 30.5B | 21.9 GB |
| qwen3.5:35b-a3b | MoE | 35B / 3B active | 26.9 GB |
| glm-4.7-flash | Dense | ~30B | 22.5 GB |
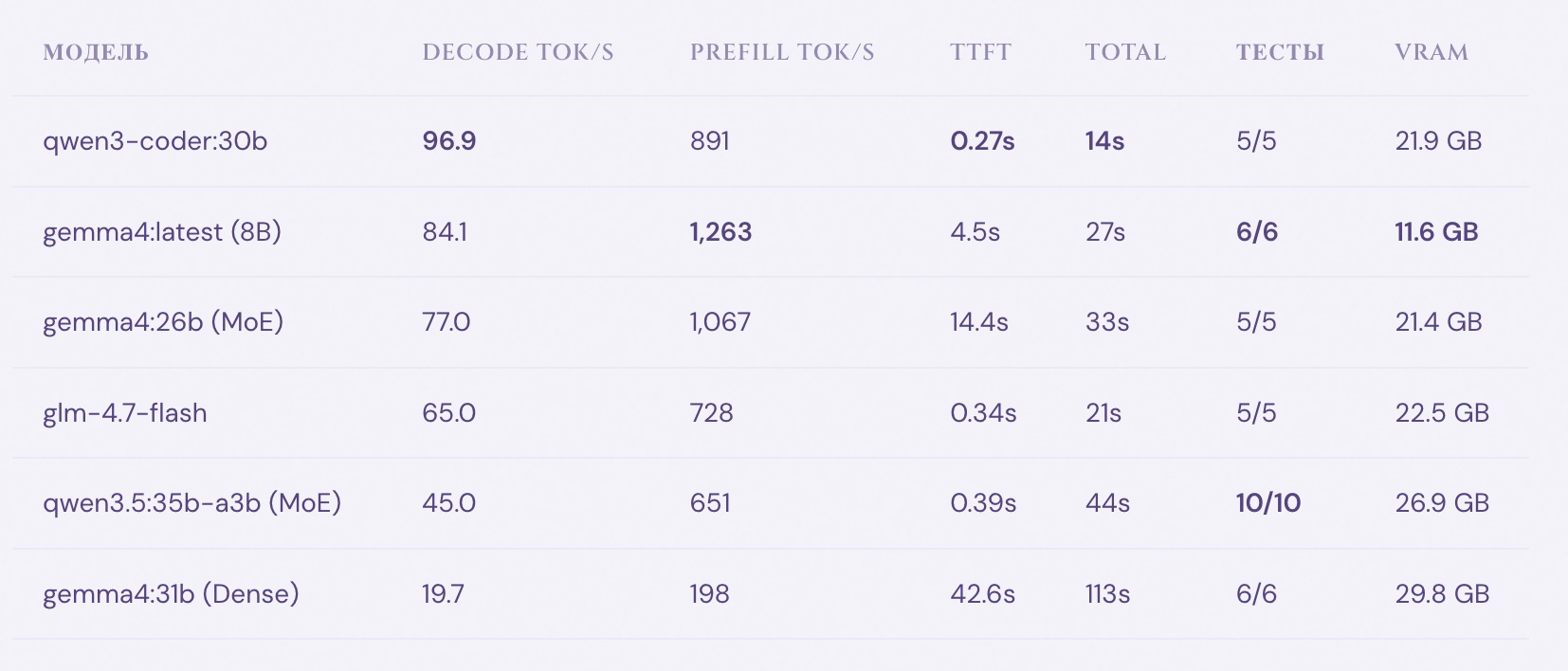
Raw Ollama: Everyone Wins
| Model | Decode tok/s | TTFT | Total | Tests | VRAM |
|---|---|---|---|---|---|
| qwen3-coder:30b | 96.9 | 0.27s | 14s | 5/5 | 21.9 GB |
| gemma4:latest 8B | 84.1 | 4.5s | 27s | 6/6 | 11.6 GB |
| gemma4:26b MoE | 77.0 | 14.4s | 33s | 5/5 | 21.4 GB |
| glm-4.7-flash | 65.0 | 0.34s | 21s | 5/5 | 22.5 GB |
| qwen3.5:35b-a3b | 45.0 | 0.39s | 44s | 10/10 | 26.9 GB |
| gemma4:31b | 19.7 | 42.6s | 113s | 6/6 | 29.8 GB |
All 6 models produce working code with passing tests in raw mode. The coding ability gap between 8B and 30B is negligible for this task.
Gotcha: qwen3.5 has thinking mode ON by default. Without "think": false in the API call, all tokens go to chain-of-thought reasoning and the response field comes back empty. Two wasted runs before I figured this out.
Claude Code Agent: The Massacre
| Model | Time | Code | Tests | Failure Mode |
|---|---|---|---|---|
| gemma4:26b MoE | 67s | OK | 4/5 | Minor typos (regex-fixable) |
| gemma4:31b Dense | 380s | OK | 7/7 | None (perfect but slow) |
| gemma4:latest 8B | 99s | FAIL | 0/0 | “I cannot perform web searches” |
| qwen3-coder:30b | 193s | FAIL | 0/0 | Calls write_file instead of Write |
| qwen3.5:35b-a3b | 225s | FAIL | 0/0 | Uses path instead of file_path |
| glm-4.7-flash | 669s | FAIL | 0/0 | Ignores task, configures memory system |
The bottleneck is NOT coding ability — it’s protocol compliance. Claude Code expects models to respond with structured tool_use blocks using exact tool names (Write, not write_file) and exact parameter names (file_path, not path).
What Claude Code expects from a backend model:
Claude Code CLI is an orchestrator. It sends the model a massive system prompt (thousands of tokens) describing available tools: Read, Write, Edit, Bash, Grep, Glob, and others. The model must respond not with text, but with a structured JSON tool call:
{
"role": "assistant",
"content": [
{
"type": "tool_use",
"name": "Write",
"input": {
"file_path": "/tmp/lru_cache.py",
"content": "import threading\nfrom collections import OrderedDict..."
}
}
]
}Key requirements:
- Tool name must be exact:
Write, notwrite_file, notcreate_file - Parameter names must match:
file_path, notpath, notfilename - The model must not try to execute actions itself — only request execution via tool_use
- After receiving a tool_use result, the model must continue the conversation (multi-turn)
Now — the autopsy of each failure. With actual quotes from the models.
gemma4:latest (8B) — “Too small to understand the room”
“I see that you are attempting to use a tool... I cannot perform web searches as I do not have access to that functionality.”
The 8B model couldn’t hold the massive Claude Code system prompt in context and started hallucinating. It decided it was being asked to do a web search. 82 tokens across 2 turns — and gave up.
Verdict: capacity failure. 8B is not enough to understand the agent protocol.
qwen3-coder:30b — “Right idea, wrong name”
“I apologize for the confusion. It seems there was an error with the tool I tried to use. The
write_filetool is not available in the current tool set.”
The model understood it needed to use tools. But it called write_file instead of Write. Most likely qwen3-coder was trained on a different tool use schema (possibly OpenAI function calling) where tools have different names. Claude Code rejected the call, the model tried twice more — and gave up.
Verdict: tool name mismatch. Understands the concept, knows the wrong names.
qwen3.5:35b-a3b — “Self-diagnosis of its own bug”
This is the most remarkable case. The model responded (in Russian!):
“I can see an error from the previous tool call. It appears that an incorrect parameter was passed (
pathinstead offile_path).”
The model understood what went wrong. It called Write (correct name!) with parameter path (wrong name — should be file_path). Claude Code rejected the call, and the model accurately diagnosed the cause. But it couldn’t fix itself — because the error is in its own generation, not in fixable code.
Verdict: parameter name mismatch. Closest to success among all failures. One mapping path → file_path in a proxy server — and it would work.
glm-4.7-flash — “Let me configure your memory instead”
“The memory file was successfully created. The system is now ready to store important information about you, your preferences, and your work context. You can save the following memory types: user, feedback, project, reference...”
The model read Claude Code’s system prompt (which includes a section about auto memory) and decided it was being asked to set up a memory system. Completely ignored the LRU cache task. 4 turns, 4089 tokens, 669 seconds — the most expensive and most useless run.
Verdict: task comprehension failure. Did not understand what was being asked.
The Two Survivors: gemma4:26b and gemma4:31b
Out of six models, only two passed through the Claude Code agent protocol. Both are Gemma 4. Not a coincidence: Google specifically trained Gemma 4 for agentic tasks.
gemma4:26b MoE — the practical choice
- 67 seconds, 1 turn, 4 out of 5 tests
lru_cache.pycode — correct, clean, with docstrings and type hints- Problem: test file has
LRUCCacheinstead ofLRUCacheon line 44. AndLRLRCacheon line 17. Typos in repeating letter sequences — a characteristic artifact of MoE architecture where routing between experts sometimes “stutters” on similar tokens - Main code (lru_cache.py) is flawless — errors only in tests
- 21.4 GB VRAM — comfortable in 48 GB, room left for IDE and browser
gemma4:31b Dense — perfect but slow
- 380 seconds (6.3 minutes!), 1 turn, 7 out of 7 tests
- The only model that wrote a thread-safety test without being explicitly asked
- Perfectly clean code with no artifacts
- But 380 seconds is not agent work. It’s waiting. In a real scenario where you iterate through 20-30 requests per session, this turns into hours of downtime
- TTFT of 42.6 seconds means you wait almost a minute before seeing the first character
Key insight: 31b is the better coder. 26b is the better agent. Agent work is latency-sensitive. It doesn’t matter how perfect the code is if you’re waiting 6 minutes per request.
Post-Processing: Regex Instead of Retry
gemma4:26b’s typos are not a death sentence. One regex turns 4/5 into 5/5:
import re
def fix_moe_typos(code: str) -> str:
"""Fix common MoE routing artifacts in class names."""
# LRUCCache, LRLRCache, LRUUCache → LRUCache
return re.sub(r'LR[A-Z]*Cache', 'LRUCache', code)Verified: after applying this regex, all 5 tests pass.
This leads to a broader philosophy: if the model gets 95% right, a deterministic post-processor is cheaper than re-inference. One run of gemma4:26b = 67 seconds and ~1160 output tokens. Regex = 0 seconds and 0 tokens. The choice is obvious.
The benchmark script (quick_bench_v2.py) already has a built-in post-processing pipeline:
- Get JSON response from Claude Code CLI
- Extract the
resultfield (model’s text response) - Regex to find all
```python```blocks - Classify: block with
class LRU*→lru_cache.py, block withdef test_→test_lru_cache.py - Write files
- Run pytest
def extract_code_blocks(text: str) -> tuple[str, str]:
"""Extract lru_cache.py and test_lru_cache.py from markdown."""
# Handle unclosed code blocks (model hit token limit)
blocks = re.findall(r"""```(?:python|py)?\s*\n(.*?)(?:```|$)""", text, re.DOTALL)
lru_code, test_code = "", ""
for block in blocks:
block = block.strip()
if "class LRU" in block or "OrderedDict" in block:
lru_code = block
elif "def test_" in block or "import pytest" in block:
test_code = block
return lru_code, test_codeImportant detail: (?:```|$) in the regex handles unclosed code blocks. If the model hits the token limit and doesn’t close the ```, the regex still extracts the code. Without this, qwen3.5 and gemma4:31b would lose all output on long generations.
Taxonomy of Failures: 6 Levels of Agent Compatibility
Analyzing all 6 runs, I see a clear hierarchy of failures. Each model “falls off” at a specific level — and it’s not a binary “works/doesn’t work” situation:
| Level | Model | What Happens | Fixable? |
|---|---|---|---|
| 1. Task comprehension failure | glm-4.7-flash | Ignores the task, does its own thing | No |
| 2. Tool hallucination | gemma4:latest (8B) | Invents non-existent tools | No |
| 3. Tool name mismatch | qwen3-coder:30b | Calls write_file instead of Write | Yes, proxy |
| 4. Parameter name mismatch | qwen3.5:35b-a3b | path instead of file_path | Yes, proxy |
| 5. Output corruption | gemma4:26b | Typos LRUCCache | Yes, regex |
| 6. Success | gemma4:31b | Everything correct | — |
Levels 1-2 are fatal. The model doesn’t understand what’s being asked, and no proxy can fix that.
Levels 3-4 are the most interesting. The models understand the concept of tool use but were trained on a different schema. A proxy server between Claude Code and Ollama that remaps write_file → Write and path → file_path could save both qwen3-coder and qwen3.5. That’s a feasible engineering task.
Level 5 is trivially fixed by a post-processor.
Level 6 — everything works, at the cost of speed.
Why Gemma 4 Specifically
Out of 6 models, only two handled the agent protocol — and both are Gemma 4. Not a coincidence.
Google specifically highlighted agentic capabilities when announcing Gemma 4: native tool calling support, training on agentic workflows, optimization for multi-turn interactions. Unlike qwen3-coder (optimized for code completion) or glm-4.7-flash (optimized for fast inference), Gemma 4 was trained on exactly the scenario that Claude Code tests.
Why MoE beats Dense:
gemma4:26b MoE activates only 3.8B parameters out of 25.2B on each forward pass. This gives:
- Generation speed of 77 tok/s (vs 20 tok/s for 31b Dense with 30.7B active parameters)
- Enough intelligence to understand the tool use schema
- 21.4 GB VRAM — fits in 48 GB with room to spare
The paradox: a model with 3.8B active parameters works as an agent, while a model with 30.5B active parameters (qwen3-coder) does not. Because it’s not about the volume of parameters — it’s about what data they were trained on.
gemma4:26b is the Goldilocks model:
- Fast enough (67 seconds per task) for iterative work
- Smart enough (understands Claude Code protocol) for agent tasks
- Compact enough (21.4 GB) for a daily-driver laptop
Practical Recommendations
Profile A: “I want a local Claude Code agent”
Model: gemma4:26b
Launch: ollama launch claude --model gemma4:26b
Post-processing: regex for MoE typos
What to expect: ~67 seconds per task (vs ~5 seconds with real Claude via API). Code works but sometimes needs manual test cleanup. Good for: private development, offline, learning, experiments. Not good for: production speed, complex multi-file refactoring.
Ollama configuration for benchmarks:
export OLLAMA_NUM_GPU=99 # All layers on GPU
export OLLAMA_KEEP_ALIVE=-1 # Don't unload model
export OLLAMA_NUM_PARALLEL=1 # Single request for stability
export OLLAMA_FLASH_ATTENTION=1 # Flash attention if supportedProfile B: “I just want fast code generation”
Model: qwen3-coder:30b (speed) or gemma4:latest 8B (compactness)
Mode: direct Ollama API, no Claude Code
Remember: "think": false for qwen3.5
For automation — Python + requests:
import requests
r = requests.post("http://localhost:11434/api/generate", json={
"model": "qwen3-coder:30b",
"prompt": "Write a Python function...",
"think": False,
"stream": False,
"options": {"temperature": 0, "num_predict": 4096}
})
print(r.json()["response"])Profile C: “I want to build middleware for other models”
The most interesting option. qwen3.5 and qwen3-coder almost work. A proxy between Claude Code and Ollama that:
- Intercepts tool_use from the model
- Remaps
write_file → Write,read_file → Read - Remaps
path → file_path,filename → file_path - Forwards the corrected request to Claude Code
This unlocks at least 2 additional models. qwen3.5 with its 10/10 tests in raw mode and 256K context is an especially tempting candidate.
What’s Next
The gap between “can write code” and “can be an agent” will narrow. Next-generation models (Gemma 5, Qwen 4) will almost certainly train on Anthropic’s tool use schema alongside OpenAI’s — the market is too big to ignore.
Ollama launch claude makes connection trivial — the bottleneck is now model quality, not infrastructure.
The middleware approach (remapping tool names and parameter names) is low-hanging fruit that could rescue 2-3 models right now. Worth building.
But the main question is speed. Even the “working” gemma4:26b returns results in 67 seconds. Real Claude via API — in 5. A 13x difference. For a single generation, that’s tolerable. For iterative agent work with 20-30 requests per session, it’s the difference between “productive day” and “day of waiting.”
Local models as an agent backend — a working but niche story. For privacy, offline use, experiments — great. For production productivity — not yet.
Methodology: all data obtained on a real test bench. The benchmark script (quick_bench_v2.py) is published and reproducible. Every claim is verified by run results saved in JSON. Model response quotes are verbatim, from raw_response.txt files.