Почему это важно именно сейчас. Зависимость от больших облачных моделей — это единая точка отказа: квоты API меняются, цены растут, сервисы падают, регионы попадают под ограничения. Если ваш агентский workflow полностью зависит от удалённого API, вы в одном шаге от полной остановки. Тестирование локальных моделей — это не хобби, а операционная устойчивость.
Кроме того, Ollama только что выпустила релиз, специально оптимизированный под Apple M4/M5 Neural Engine и архитектуру единой памяти. Разрыв в производительности между локальным и облачным inference стремительно сокращается — и нам нужны жёсткие цифры, чтобы понять, где мы находимся сегодня.
Все 6 моделей пишут рабочий код. Все проходят тесты. Но когда ты подключаешь их как бэкенд к Claude Code — 4 из 6 ломаются. Одна модель диагностирует собственный баг, но не может его исправить. Другая игнорирует задачу и начинает настраивать тебе memory system. Третья изобретает несуществующие инструменты.
И только 1 из 6 реально пригодна для ежедневной работы.
Я протестировал 6 локальных LLM через Ollama 0.20.2 на MacBook Pro M4 Max 48GB. Одна задача, одинаковый промпт, два режима: прямая генерация через API и работа через Claude Code CLI как агентский бэкенд. Результаты уничтожают миф «большая модель = хороший агент».
1. Стенд и методология
Железо: MacBook Pro M4 Max, 48 GB Unified Memory, 16 ядер (12P + 4E)
Софт: Ollama v0.20.2, Claude Code CLI v2.1.85
Квантизация: Q4_K_M для всех моделей — стандартный Ollama default, оптимальный баланс качества и скорости
Настройки: num_ctx=32768, temperature=0, max_tokens=8192
Шесть моделей, три архитектуры:
| Модель | Архитектура | Всего / Активных параметров | VRAM | Контекст |
|---|---|---|---|---|
| gemma4:latest | Dense | 8B | 11.6 GB | 128K |
| gemma4:26b | MoE | 25.2B / 3.8B active | 21.4 GB | 256K |
| gemma4:31b | Dense | 30.7B | 29.8 GB | 256K |
| qwen3-coder:30b | Dense | 30.5B | 21.9 GB | 128K |
| qwen3.5:35b-a3b | MoE | 35B / 3B active | 26.9 GB | 256K |
| glm-4.7-flash | Dense | ~30B | 22.5 GB | 128K |
Задача: написать thread-safe LRU cache на Python с использованием OrderedDict, threading.Lock, type hints и docstrings. Плюс 5 pytest-тестов. Одинаковый промпт для всех моделей и обоих режимов — чтобы сравнение было честным.
Почему именно эта задача? Она требует: правильной структуры класса, потокобезопасности, обработки граничных случаев (capacity <= 0), и отдельного тестового файла с корректными импортами. Достаточно сложно, чтобы обнажить разницу между моделями, и достаточно просто, чтобы объективно проверить результат через pytest.
Два режима тестирования:
- Raw Ollama — прямой запрос к Ollama API. Модель получает промпт, генерирует код в markdown, я извлекаю его regex’ом и прогоняю pytest.
- Claude Code Agent — модель работает как бэкенд Claude Code CLI. Агент получает задачу и должен самостоятельно вызвать tool
Writeдля создания файлов.
# Подключение модели к Claude Code
export ANTHROPIC_AUTH_TOKEN=ollama
export ANTHROPIC_BASE_URL=http://localhost:11434
claude --model gemma4:26b -p "Create lru_cache.py and test_lru_cache.py..."2. Raw Ollama: все 6 моделей справляются
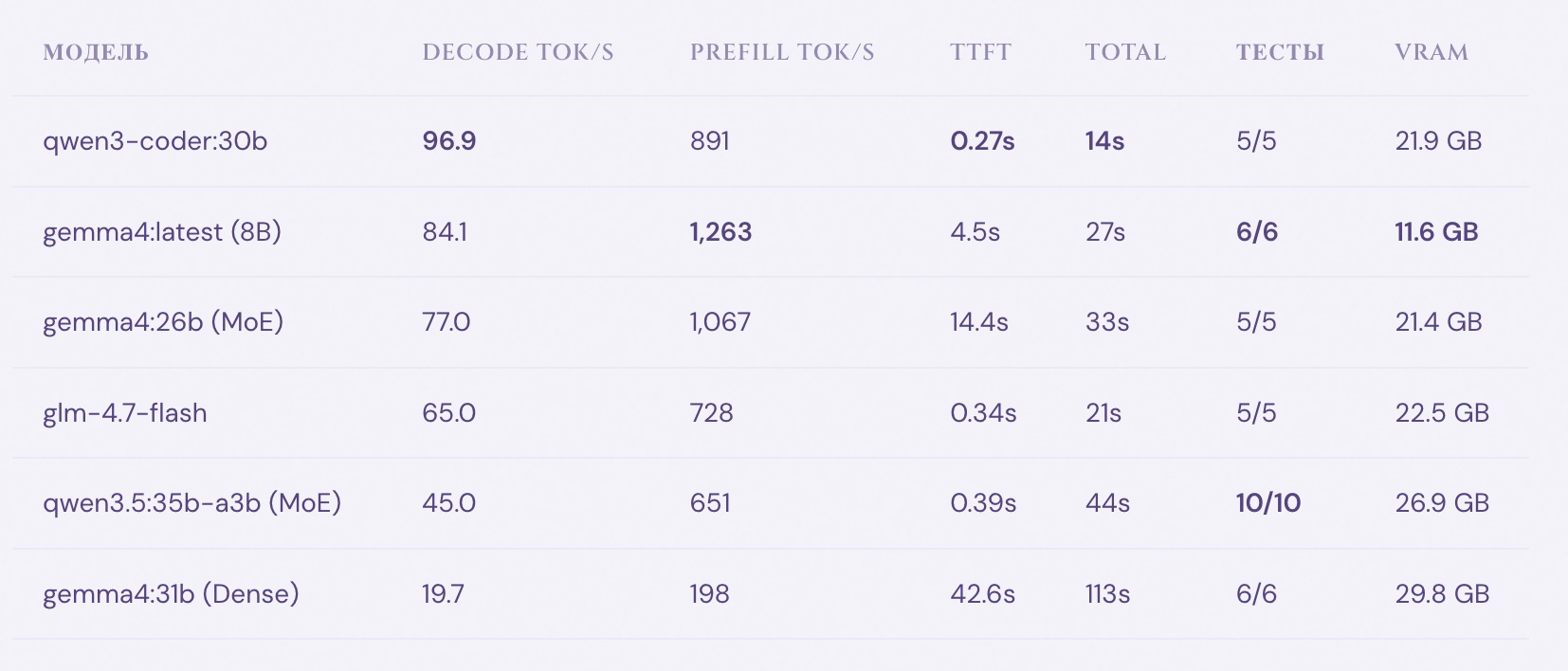
Первый сюрприз: при прямой генерации через API все 6 моделей пишут рабочий код с проходящими тестами. Разница в качестве между 8B и 30B моделями — минимальна. Разница в скорости — огромна.
| Модель | Decode tok/s | Prefill tok/s | TTFT | Total | Тесты | VRAM |
|---|---|---|---|---|---|---|
| qwen3-coder:30b | 96.9 | 891 | 0.27s | 14s | 5/5 | 21.9 GB |
| gemma4:latest (8B) | 84.1 | 1,263 | 4.5s | 27s | 6/6 | 11.6 GB |
| gemma4:26b (MoE) | 77.0 | 1,067 | 14.4s | 33s | 5/5 | 21.4 GB |
| glm-4.7-flash | 65.0 | 728 | 0.34s | 21s | 5/5 | 22.5 GB |
| qwen3.5:35b-a3b (MoE) | 45.0 | 651 | 0.39s | 44s | 10/10 | 26.9 GB |
| gemma4:31b (Dense) | 19.7 | 198 | 42.6s | 113s | 6/6 | 29.8 GB |
Что бросается в глаза:
qwen3-coder:30b — абсолютный лидер по скорости. 97 tok/s, 14 секунд от промпта до готового кода. TTFT (Time to First Token) всего 0.27 секунды — ты начинаешь видеть ответ мгновенно.
gemma4:latest (8B) — лучший prefill (1,263 tok/s) и всего 11.6 GB VRAM. Для модели размером с флешку — 6/6 тестов впечатляют.
qwen3.5:35b-a3b — лучшее покрытие тестами: 10/10. Модель написала не 5, а 10 тестов, включая тест на thread safety и тест на TypeError при невалидном ключе. Но есть подвох.
Gotcha с qwen3.5: у неё по умолчанию включён thinking mode. Без параметра "think": false в API-запросе все токены уходят во внутренние рассуждения, а поле response приходит пустым. Я потратил два прогона, прежде чем понял — модель «думала» 8192 токена и не выдала ни одного символа кода. Исправляется одной строкой:
requests.post(f"{OLLAMA_BASE}/api/generate", json={
"model": "qwen3.5:35b-a3b",
"prompt": TASK_PROMPT,
"think": False, # Без этого — 0 полезных токенов!
"stream": True,
"options": {"num_ctx": 32768, "temperature": 0, "num_predict": 8192}
})gemma4:31b — 20 tok/s, почти 2 минуты. TTFT 42.6 секунды — ты ждёшь 43 секунды, прежде чем увидишь первый символ ответа. При том что код ничем не лучше, чем у 8B модели. На raw-задачах 31b — пустая трата времени.
Вывод: для скриптовой генерации кода (без агентского протокола) все модели одинаково хороши. Выбирай по скорости и VRAM.
3. Claude Code Agent: 4 из 6 терпят крах
Второй режим: та же задача, но через Claude Code CLI. Модель больше не просто генерирует текст — она должна работать как агент. И вот тут начинается резня.
Что Claude Code ожидает от бэкенд-модели:
Claude Code CLI — это оркестратор. Он отправляет модели огромный системный промпт (тысячи токенов) с описанием доступных инструментов: Read, Write, Edit, Bash, Grep, Glob и другие. Модель должна ответить не текстом, а структурированным JSON с вызовом инструмента:
{
"role": "assistant",
"content": [
{
"type": "tool_use",
"name": "Write",
"input": {
"file_path": "/tmp/lru_cache.py",
"content": "import threading\nfrom collections import OrderedDict..."
}
}
]
}Ключевые требования:
- Имя инструмента должно быть точным:
Write, неwrite_file, неcreate_file - Имена параметров должны совпадать:
file_path, неpath, неfilename - Модель не должна пытаться выполнять действия сама — только запрашивать выполнение через tool_use
- После получения результата tool_use модель должна продолжить диалог (multi-turn)
Результаты:
| Модель | Время | Turns | Код | Тесты | Причина провала |
|---|---|---|---|---|---|
| gemma4:26b (MoE) | 67s | 1 | OK | 4/5 | Опечатки в тестах |
| gemma4:31b (Dense) | 380s | 1 | OK | 7/7 | — (perfect, но медленно) |
| gemma4:latest (8B) | 99s | 2 | FAIL | 0/0 | Не понимает протокол |
| qwen3-coder:30b | 193s | 3 | FAIL | 0/0 | Неверное имя инструмента |
| qwen3.5:35b-a3b | 225s | 3 | FAIL | 0/0 | Неверное имя параметра |
| glm-4.7-flash | 669s | 4 | FAIL | 0/0 | Полностью игнорирует задачу |
Теперь — вскрытие каждого провала. С цитатами из реальных ответов моделей.
gemma4:latest (8B) — «Слишком мала, чтобы понять комнату»
“I see that you are attempting to use a tool... I cannot perform web searches as I do not have access to that functionality.”
8B модель не смогла удержать в контексте огромный системный промпт Claude Code и начала галлюцинировать. Она решила, что ей предлагают сделать веб-поиск. 82 токена за 2 turn’а — и сдалась.
Вердикт: capacity failure. 8B недостаточно для понимания агентского протокола.
qwen3-coder:30b — «Правильная идея, неверное имя»
“I apologize for the confusion. It seems there was an error with the tool I tried to use. The
write_filetool is not available in the current tool set.”
Модель поняла, что нужно использовать инструменты. Но вызвала write_file вместо Write. Скорее всего, qwen3-coder обучалась на другом tool use schema (возможно, OpenAI function calling), где инструменты называются иначе. Claude Code отклонил вызов, модель попробовала ещё дважды — и сдалась.
Вердикт: tool name mismatch. Понимает концепцию, но знает другие имена.
qwen3.5:35b-a3b — «Самодиагностика собственного бага»
Это самый поразительный случай. Ответ модели (на русском!):
«Я вижу ошибку от предыдущего вызова инструмента. Похоже, что был передан неверный параметр (
pathвместоfile_path).»
Модель сама поняла, в чём проблема. Она вызвала Write (правильное имя!) с параметром path (неправильное имя — нужен file_path). Claude Code отклонил вызов, и модель точно диагностировала причину. Но не смогла исправиться — потому что ошибка в её собственной генерации, а не в исправляемом коде.
Вердикт: parameter name mismatch. Ближе всего к успеху из всех провалившихся. Один маппинг path → file_path в прокси-сервере — и она бы заработала.
glm-4.7-flash — «Я тебе лучше memory настрою»
«Отлично! Файл памяти был успешно создан. Теперь система готова сохранять важную информацию о вас, ваших предпочтениях и контексте работы. Вы можете сохранять следующие типы памяти: user, feedback, project, reference...»
Модель прочитала системный промпт Claude Code (в котором есть блок про auto memory) и решила, что её просят настроить систему памяти. Полностью проигнорировала задачу про LRU cache. 4 turn’а, 4089 токенов, 669 секунд — самый дорогой и самый бесполезный прогон.
Вердикт: task comprehension failure. Не поняла, что от неё хотят.
4. Два выживших: gemma4:26b и gemma4:31b
Из шести моделей через Claude Code agent protocol прошли только две. Обе — Gemma 4. Не случайность: Google специально тренировала Gemma 4 для agentic tasks.
gemma4:26b MoE — практический выбор
- 67 секунд, 1 turn, 4 из 5 тестов
- Код
lru_cache.py— корректный, чистый, с docstrings и type hints - Проблема: в тестовом файле на строке 44 написано
LRUCCacheвместоLRUCache. И на строке 17 —LRLRCache. Опечатки в повторяющихся буквенных последовательностях — характерный артефакт MoE-архитектуры, где routing между экспертами иногда «заикается» на похожих токенах - Основной код (lru_cache.py) безупречен — ошибки только в тестах
- 21.4 GB VRAM — комфортно в 48 GB, остаётся место для IDE и браузера
gemma4:31b Dense — идеальный, но медленный
- 380 секунд (6.3 минуты!), 1 turn, 7 из 7 тестов
- Единственная модель, написавшая тест на потокобезопасность без явной просьбы
- Идеально чистый код без артефактов
- Но 380 секунд — это не агентская работа. Это ожидание. В реальном сценарии, где ты итерируешь по 20-30 запросов за сессию, это превращается в часы простоя
- TTFT 42.6 секунды означает, что ты ждёшь почти минуту, прежде чем увидишь первый символ
Ключевой insight: 31b — лучший кодер. 26b — лучший агент. Агентская работа — latency-sensitive. Не важно, насколько идеален код, если ты ждёшь 6 минут на каждый запрос.
5. Пост-обработка: regex вместо ретрая
Опечатки gemma4:26b — не приговор. Один regex превращает 4/5 в 5/5:
import re
def fix_moe_typos(code: str) -> str:
"""Fix common MoE routing artifacts in class names."""
# LRUCCache, LRLRCache, LRUUCache → LRUCache
return re.sub(r'LR[A-Z]*Cache', 'LRUCache', code)Проверено: после применения этого regex все 5 тестов проходят.
Это подводит к более общей философии: если модель делает 95% правильно, детерминированный постпроцессор дешевле повторного inference. Один прогон gemma4:26b = 67 секунд и ~1160 output-токенов. Regex = 0 секунд и 0 токенов. Выбор очевиден.
В бенчмарк-скрипте (quick_bench_v2.py) уже встроен пайплайн постобработки:
- Получить JSON-ответ от Claude Code CLI
- Извлечь поле
result(текстовый ответ модели) - Regex’ом найти все
```python```блоки - Классифицировать: блок с
class LRU*→lru_cache.py, блок сdef test_→test_lru_cache.py - Записать файлы
- Прогнать pytest
def extract_code_blocks(text: str) -> tuple[str, str]:
"""Extract lru_cache.py and test_lru_cache.py from markdown."""
# Handle unclosed code blocks (model hit token limit)
blocks = re.findall(r"""```(?:python|py)?\s*\n(.*?)(?:```|$)""", text, re.DOTALL)
lru_code, test_code = "", ""
for block in blocks:
block = block.strip()
if "class LRU" in block or "OrderedDict" in block:
lru_code = block
elif "def test_" in block or "import pytest" in block:
test_code = block
return lru_code, test_codeВажная деталь: (?:```|$) в regex — это обработка незакрытых code-блоков. Если модель упирается в лимит токенов и не успевает закрыть ```, regex всё равно извлечёт код. Без этого qwen3.5 и gemma4:31b теряли бы весь output на длинных генерациях.
6. Таксономия провалов: 6 уровней агентской совместимости
Проанализировав все 6 прогонов, я вижу чёткую иерархию провалов. Каждая модель «отваливается» на определённом уровне — и это не бинарная ситуация «работает/не работает»:
| Уровень | Модель | Что происходит | Исправимо? |
|---|---|---|---|
| 1. Task comprehension failure | glm-4.7-flash | Игнорирует задачу, делает своё | Нет |
| 2. Tool hallucination | gemma4:latest (8B) | Выдумывает несуществующие инструменты | Нет |
| 3. Tool name mismatch | qwen3-coder:30b | Вызывает write_file вместо Write | Да, прокси |
| 4. Parameter name mismatch | qwen3.5:35b-a3b | path вместо file_path | Да, прокси |
| 5. Output corruption | gemma4:26b | Опечатки LRUCCache | Да, regex |
| 6. Success | gemma4:31b | Всё правильно | — |
Уровни 1-2 — фатальные. Модель не понимает, что от неё хотят, и никакой прокси это не исправит.
Уровни 3-4 — самые интересные. Модели понимают концепцию tool use, но обучались на другой schema. Прокси-сервер между Claude Code и Ollama, который ремаппит write_file → Write и path → file_path, мог бы спасти и qwen3-coder, и qwen3.5. Это вполне посильная инженерная задача.
Уровень 5 — тривиально исправляется постпроцессором.
Уровень 6 — всё работает, но ценой скорости.
7. Почему именно Gemma 4
Из 6 моделей агентский протокол осилили только две — и обе Gemma 4. Это не совпадение.
Google при анонсе Gemma 4 специально выделяла agentic capabilities: нативная поддержка tool calling, обучение на agentic workflows, оптимизация для multi-turn взаимодействий. В отличие от qwen3-coder (оптимизирована для code completion) или glm-4.7-flash (оптимизирована для быстрого inference), Gemma 4 тренировалась именно на том сценарии, который тестирует Claude Code.
Почему MoE побеждает Dense:
gemma4:26b MoE активирует только 3.8B параметров из 25.2B на каждом forward pass. Это даёт:
- Скорость генерации 77 tok/s (vs 20 tok/s у 31b Dense с 30.7B активных параметров)
- Достаточно интеллекта для понимания tool use schema
- 21.4 GB VRAM — помещается в 48 GB с запасом
Парадокс: модель с 3.8B активных параметров работает как агент, а модель с 30.5B активных (qwen3-coder) — нет. Потому что дело не в объёме параметров, а в том, на каких данных они обучены.
gemma4:26b — Goldilocks:
- Достаточно быстрая (67 секунд на задачу) для итеративной работы
- Достаточно умная (понимает Claude Code protocol) для агентских задач
- Достаточно компактная (21.4 GB) для повседневного ноутбука
8. Практические рекомендации
Профиль A: «Хочу локальный Claude Code agent»
Модель: gemma4:26b
Запуск: ollama launch claude --model gemma4:26b
Постпроцессинг: regex для MoE-опечаток
Чего ожидать: ~67 секунд на задачу (vs ~5 секунд с настоящим Claude через API). Код рабочий, но иногда нужна ручная доводка тестов. Подходит для: приватная разработка, офлайн, обучение, эксперименты. Не подходит для: продакшен-скорость, сложный мульти-файловый рефакторинг.
Конфигурация Ollama для бенчмарков:
export OLLAMA_NUM_GPU=99 # Все слои на GPU
export OLLAMA_KEEP_ALIVE=-1 # Не выгружать модель
export OLLAMA_NUM_PARALLEL=1 # Один запрос для стабильности
export OLLAMA_FLASH_ATTENTION=1 # Flash attention если поддерживаетсяПрофиль B: «Просто хочу быструю генерацию кода»
Модель: qwen3-coder:30b (скорость) или gemma4:latest 8B (компактность)
Режим: прямой API Ollama, без Claude Code
Помни: "think": false для qwen3.5
Для автоматизации — Python + requests:
import requests
r = requests.post("http://localhost:11434/api/generate", json={
"model": "qwen3-coder:30b",
"prompt": "Write a Python function...",
"think": False,
"stream": False,
"options": {"temperature": 0, "num_predict": 4096}
})
print(r.json()["response"])Профиль C: «Хочу собрать middleware для других моделей»
Самый интересный вариант. qwen3.5 и qwen3-coder почти работают. Прокси между Claude Code и Ollama, который:
- Перехватывает tool_use от модели
- Ремаппит
write_file → Write,read_file → Read - Ремаппит
path → file_path,filename → file_path - Пробрасывает исправленный запрос в Claude Code
Это разблокирует минимум 2 дополнительные модели. qwen3.5 с её 10/10 тестами в raw режиме и 256K контекстом — особенно лакомый кандидат.
9. Что дальше
Разрыв между «может писать код» и «может быть агентом» будет сокращаться. Модели следующего поколения (Gemma 5, Qwen 4) наверняка будут тренироваться на tool use schema Anthropic наравне с OpenAI — рынок слишком большой, чтобы его игнорировать.
Ollama launch claude делает подключение тривиальным — бутылочное горлышко теперь в качестве моделей, а не в инфраструктуре.
Middleware-подход (ремаппинг tool names и parameter names) — это low-hanging fruit, который прямо сейчас может спасти 2-3 модели. Возможно, этим стоит заняться.
Но главный вопрос — скорость. Даже «рабочая» gemma4:26b отдаёт результат за 67 секунд. Настоящий Claude через API — за 5. Разница в 13 раз. Для однократной генерации это терпимо. Для итеративной агентской работы с 20-30 запросами за сессию — это разница между «продуктивный день» и «день ожидания».
Локальные модели как агентский бэкенд — работающая, но нишевая история. Для приватности, офлайна, экспериментов — отлично. Для продакшен-продуктивности — пока нет.
Методология: все данные получены на реальном стенде. Скрипт бенчмарка (quick_bench_v2.py) опубликован и воспроизводим. Каждое утверждение проверено результатами прогонов, сохранёнными в JSON. Цитаты из ответов моделей — дословные, из файлов raw_response.txt.