Philip K. Dick asked the question about androids. I'm asking it about AI agents. Because Datarim has a command called /dr-dream, and the agent genuinely "falls asleep." A librarian agent sifts through the project knowledge base, finds contradictions, builds cross-references, throws out garbage. Wakes up with a clear head.
Sounds like science fiction. It's working code. MIT license. On GitHub. Right now.
Here's what I'm arguing: a framework is not a tool. It's an operating system for AI development. Not "help me write a function," but "here's a backlog of 40 tasks, pick the next one, take it from requirements to archival, learn from your mistakes, suggest process improvements."
AI agents can write code. That's old news. But they can't run projects. Hand Claude Code a task with no structure and it'll write code, maybe even working code. But it won't ask about requirements. Won't assess complexity. Won't write tests before code. Won't do a review. Won't document what it learned. Won't pick the next task from the queue.
Datarim gives the agent that structure: backlog → task → complexity assessment → requirements → plan → implementation → verification → reflection → archival → next task.
I've closed over a thousand tasks in one year. Solo. On a $200/month subscription. No dev team. No project manager. No QA engineer. The agent does all of it, following Datarim's rules. I'm not claiming "this replaces a team." I'm saying one person with the right framework operates at the capacity of a small studio.
And no, I'm not a genius or a workaholic pulling 16-hour days. I just stopped re-explaining the same things to the agent every session.
Where It Came From
It started small. In March 2025, vanzan01 published cursor-memory-bank on GitHub — a simple memory bank for the Cursor IDE. The idea was basic: the agent remembers project context between sessions. Structure, stack, architecture decisions. No magic, just markdown files loaded at the start of each conversation.
I liked the idea but wanted more. I forked it and built cursor-memory-bank-angry. "Angry" from Angry Robot Deals, my company at the time. I added workflow management commands. Made TDD mandatory. Created a backlog. Bolted on an SDLC framework with task decomposition and automatic stack selection.
It worked better, but it was still tied to Cursor and to code. I wanted a system that manages any project, not just software. Research. Articles. Legal documents. DevOps infrastructure. SEO audits.
That's how Datarim v1.3.0 was born — a full platform. 15 agents, 18 skills, 19 commands, 5 templates, a 9-stage pipeline. Built for Claude Code, though the architecture isn't locked to any specific provider.
Links, if you want to trace the evolution:
- Original: https://github.com/vanzan01/cursor-memory-bank
- Intermediate: https://github.com/Angry-Robot-Deals/cursor-memory-bank-angry
- Datarim: https://github.com/Arcanada-one/datarim
How It Works
A 9-stage pipeline:
init → prd → plan → design → do → qa → compliance → reflect → archiveNot every task goes through all 9. That would be absurd — running a bug fix through architectural design review. So there's complexity routing:
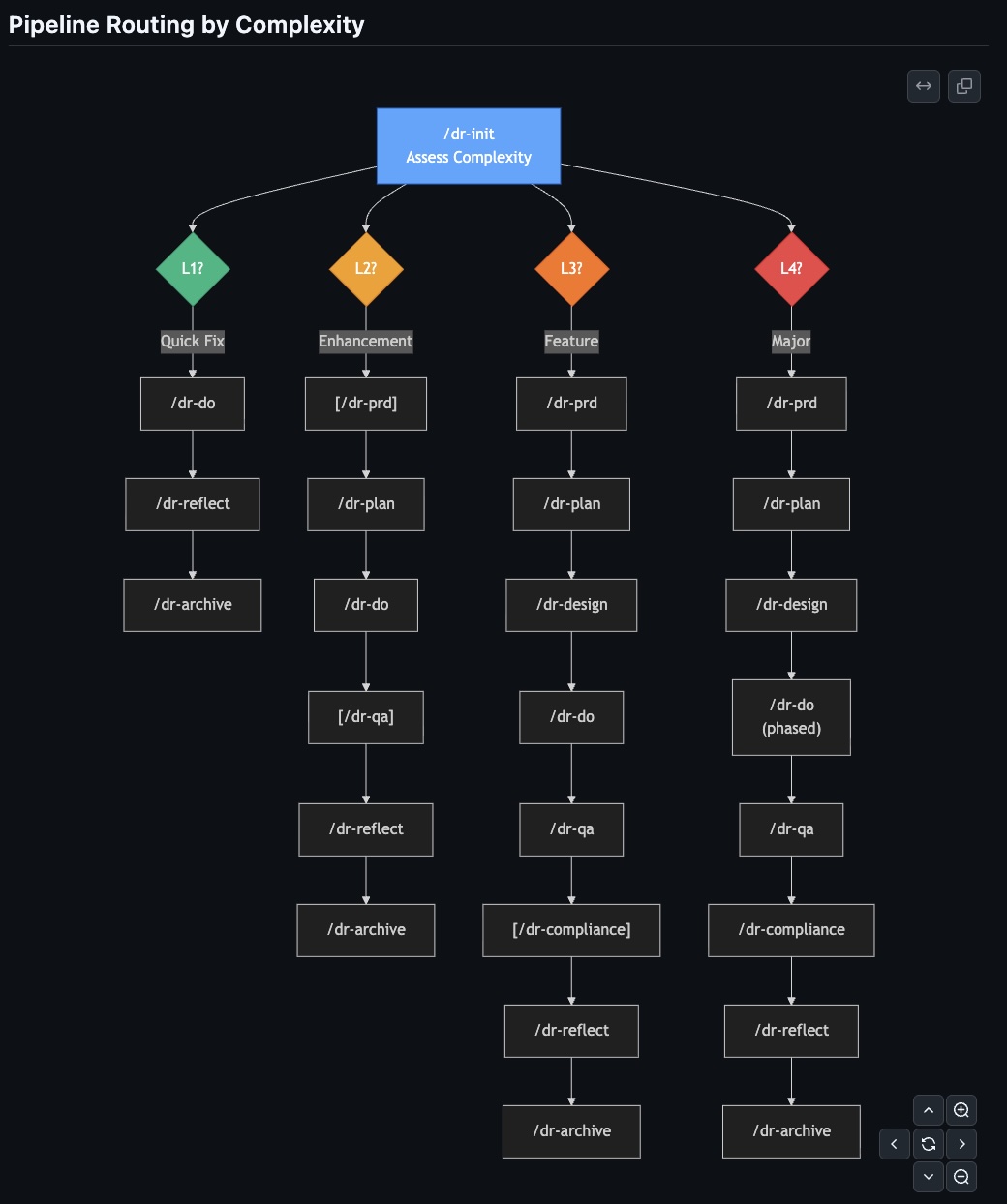
| Level | What it is | Pipeline |
|---|---|---|
| L1 Quick Fix | 1 file, <50 LOC | init → do → reflect → archive |
| L2 Enhancement | 2-5 files, <200 LOC | init → [prd] → plan → do → [qa] → reflect → archive |
| L3 Feature | 5-15 files, 200-1000 LOC | init → prd → plan → design → do → qa → [compliance] → reflect → archive |
| L4 Major Feature | 15+ files, >1000 LOC | init → prd → plan → design → phased-do → qa → compliance → reflect → archive |
Brackets mean optional at that level. An L1 task closes in 4 steps. L4 goes through all 9.
15 Agents
Each agent is a specialized role. Not the same Claude wearing different hats, but a different set of skills, rules, and context for each role:
| Agent | Role | When it works |
|---|---|---|
| planner | Lead Project Manager | init, plan, archive |
| architect | Chief Architect | prd, design |
| developer | Senior Developer (TDD) | do |
| reviewer | QA & Security Lead | qa, reflect |
| compliance | Compliance Runner | compliance |
| code-simplifier | Code Simplification | compliance |
| strategist | Strategic Advisor | plan (L3-4) |
| devops | DevOps Engineer | plan, do, compliance |
| writer | Content Writer | write, reflect, archive, prd |
| editor | Content Editor | edit, qa (content) |
| skill-creator | Skill/Agent/Command Creator | addskill |
| optimizer | Framework Optimizer | optimize, reflect |
| librarian | Knowledge Base Librarian | dream |
| security | Security Analyst | design, qa, compliance |
| sre | Site Reliability Engineer | design, qa, reflect |
Not all agents load for every task. An L1 fix loads developer and maybe reviewer. An L4 project pulls in planner, architect, developer, reviewer, strategist, and whoever else is needed.
18 Skills
Skills are knowledge modules. Not code — rules and patterns the agent loads on demand:
- datarim-system — core, always loaded
- ai-quality — TDD, decomposition, cognitive load management
- compliance — 7-step hardening workflow
- security — auth, validation, data protection
- testing — testing pyramid, mocking rules
- performance — optimization patterns
- tech-stack — stack selection by project type
- utilities — shell recipes for common operations
- consilium — multi-agent panel discussions
- discovery — requirements gathering interview
- evolution — framework self-update rules
- writing — content creation and editorial workflow
- dream — knowledge base maintenance rules
- seo-launch — SEO, analytics, launch checklists
- marketing — ad campaigns, conversion tracking, landing pages
- factcheck — fact verification for publications
- humanize — AI text pattern removal
- visual-maps — Mermaid workflow diagrams
Autonomous Work in Practice
Picture this: the backlog has task BACKLOG-0042 "Add JWT authentication to API." The agent picks it up:
/dr-init— loads the task, assesses complexity as L3/dr-prd— architect defines requirements: token format, expiration, refresh flow, protected routes/dr-plan— planner + strategist break it into phases: middleware, token service, login endpoint, tests/dr-design— consilium: architect + security discuss JWT vs session tokens, make a decision/dr-do— developer writes code via TDD: tests first, then implementation, one method per iteration/dr-qa— reviewer verifies: PRD alignment, security review, test coverage, OWASP checks/dr-reflect— reviewer notes: "refresh token rotation was underestimated during planning"/dr-archive— planner archives the task, updates backlog, picks up the next one
The full cycle. Without me hovering over every step. I set the direction and review the results.
A Framework That Thinks About Itself
You could write a pipeline in a day. Three mechanisms I haven't seen in any other framework? Those you can't.
Reflection
/dr-reflect runs after every task. The reviewer agent analyzes what went well, what went wrong, and proposes specific improvements. Not vague stuff like "we should plan better," but "the security skill doesn't cover rate limiting — add a section." Or "the developer agent spends too many tokens re-reading files — add a caching rule to ai-quality.md."
Proposals get recorded. A human approves or rejects. The framework updates. The next task runs better.
Over a year, Datarim has gone through dozens of these cycles. The skills that exist today weren't planned from the start. factcheck appeared after I published an article with inaccurate numbers. humanize — after a LinkedIn post read like typical ChatGPT output. seo-launch — after manually launching a third website in a row.
Dream
/dr-dream is the librarian. An agent that doesn't write code or create content. It organizes the project knowledge base: the datarim/ directory, all state files, archives, reflections.
- Finds contradictions between documents (techContext.md says "Express" but the code uses Fastify)
- Builds cross-references
- Removes outdated information
- Reorganizes misplaced files
- Updates indexes
I run it every week or two. After a big sprint or before starting a new project phase. Clean knowledge base = fewer agent hallucinations.
Optimize
/dr-optimize audits the framework itself. The optimizer agent checks all 18 skills, 15 agents, 19 commands. It looks for:
- Unused skills (loaded but their rules aren't applied)
- Duplicates (two skills describing the same thing in different words)
- Broken references between files
- Drift between documentation and reality
When a framework grows organically through reflection, entropy accumulates. Optimize fights that.
Consilium
For critical decisions (L3-L4), Datarim assembles a panel of agents. Architect proposes architecture, Security looks for vulnerabilities, DevOps calculates operational costs, SRE thinks about reliability. They debate. The outcome is a weighed decision.
This isn't synthetic crowd wisdom. Each agent loads its own skill set and sees the task through its own lens. Architect optimizes for scalability, Security for protection, SRE for observability. The tension between them is the value.
What Datarim Is Not
Three misconceptions that come up most often.
A Memory Layer (mem0.ai)
Datarim is not mem0.ai or anything like it. Mem0 solves a different problem: persistent agent memory. Who you are, what you like, what decisions you made before. That's useful, but it's a different layer.
Datarim is project execution structure. What to do. In what order. With what quality checks at each step. How to learn from results. Mem0 remembers that you like TypeScript. Datarim makes sure you wrote tests before code, did a review, documented decisions, and updated the backlog.
Different layers. Compatible. You can use both.
A Multi-Agent Orchestrator (AutoGPT, CrewAI)
Datarim is not a multi-agent orchestrator running agents in parallel. There's no complex real-time message routing between agents. One agent per stage. Clear pipeline. The next agent gets the previous one's output through files in datarim/.
This is simpler than CrewAI. And more reliable. Multi-agent systems with parallel execution look great in diagrams but produce coordination problems that are painful to debug. Datarim chooses sequence and predictability.
A Code-Only Tool
This is probably the most common misconception. Yes, Datarim grew out of software development. But the pipeline — requirements → plan → execution → verification → reflection — is universal.
Real use cases from the documentation:
- Legal documents (SaaS Terms of Service)
- Academic research (literature reviews, methodology)
- Technical documentation (API docs, architecture decisions)
- Project management (backlogs, iterations, retrospectives)
- Content (articles, posts, with fact-checking)
- DevOps (CI/CD, Docker, deployments)
- SRE (observability, SLOs, incident response)
- SEO (audits, analytics, Search Console)
- Ad campaigns (Google Ads, structure, tracking)
- App Store publishing (metadata, screenshots, privacy policy)
- Website launches (pre-launch checklist, SSL, OG tags)
- UI/UX (landing pages, components, responsiveness)
This article you're reading right now was written through Datarim. Task CONTENT-0001. Pipeline: init → plan → write → edit → archive.
Who It's For
Datarim works well if you're:
- A solo developer who wants to get the most out of Claude Code
- A startup where one or two people do the work of ten
- A researcher running a large project with many tasks
- A content team that needs an editorial process with fact-checking
- Anyone who works with AI agents and is tired of chaotic freestyle
Datarim is not for you if you:
- Don't use AI agents (the framework without an agent is just markdown files)
- Write throwaway scripts (the overhead isn't worth it)
If you already have Jira, Asana, CI/CD, and code review — great. Datarim doesn't replace your SDLC, it works inside it. I pull a task from Asana, run /dr-init, and the agent takes it through the pipeline. The project backlog lives in your tracker, the task-level execution lives in Datarim. Different layers.
A note on models. Datarim is built with limited context in mind. At each stage, the agent loads the minimum necessary information: only the relevant skill, only the current task state, only the files referenced in the plan. Not the whole project. This means the framework works on models with smaller context windows too. Not perfectly, but it works.
Quick Start
Five minutes from zero to your first task.
git clone https://github.com/Arcanada-one/datarim.git
cd datarim && ./install.shThe script places agents, skills, and commands in the right directories. Then:
cp CLAUDE.md /path/to/your/project/
cd /path/to/your/project/
claudeIn Claude Code:
/dr-help # See all commands with descriptions
/dr-init <task> # Start workingFirst task for beginners: try an L1. Describe a simple bug fix or minor improvement. /dr-init "Fix typo in README". The agent assesses L1, runs init → do → reflect → archive. You'll see the full cycle in 5 minutes. Then try L2 — with a plan. Then L3 — with design and consilium.
MIT license. Fork it, adapt it, contribute.
GitHub: https://github.com/Arcanada-one/datarim
What's Next
I won't sugarcoat this with vague optimism. Here's what I know.
Datarim is a framework I use every day for real work. A thousand tasks in a year — that's not a marketing number, it's my backlog archive. Every task left a reflection, and every reflection made the framework a little better.
If you work with AI agents and feel like the freestyle approach is hitting a ceiling — give it a shot. Clone it, run /dr-init, close a few tasks. If it doesn't click, you've spent thirty minutes. If it does, you'll save hundreds of hours.
The repo is open. Contributors welcome. Issues too.