Филип Дик задал вопрос про андроидов. Я задаю его про AI-агентов. Потому что в Datarim есть команда /dr-dream, и агент действительно "засыпает". Библиотекарь-агент перебирает базу знаний проекта, находит противоречия, строит перекрёстные ссылки, выбрасывает мусор. Просыпается с чистой головой.
Звучит как фантазия. Но это работающий код. MIT-лицензия. GitHub. Прямо сейчас.
Вопрос, который я ставлю: что если фреймворк это не инструмент, а операционная система для AI-разработки? Не "помоги мне написать функцию", а "вот бэклог из 40 задач, бери следующую, веди её от требований до архивации, учись на ошибках, предлагай улучшения процесса".
AI-агенты умеют писать код. Это уже не новость. Но они не умеют вести проекты. Дай Claude Code задачу без структуры, он напишет код, может даже рабочий. Но он не спросит про требования. Не оценит сложность. Не напишет тесты до кода. Не проведёт ревью. Не задокументирует, что выучил. Не подберёт следующую задачу из очереди.
Datarim даёт агенту эту структуру: бэклог → задача → оценка сложности → требования → план → реализация → проверка → рефлексия → архивация → следующая задача.
Я закрыл больше тысячи задач за год. Один. С подпиской в $200 в месяц. Без команды разработки. Без менеджера проектов. Без QA-инженера. Всё это делает агент, работающий по правилам Datarim. Я не говорю "это заменит команду". Я говорю, что один человек с правильным фреймворком работает с производительностью маленькой студии.
И нет, я не гений и не работаю 16 часов в сутки. Я просто перестал объяснять агенту одно и то же каждую сессию.
Откуда это взялось
Начиналось всё скромно. В марте 2025 года vanzan01 выложил на GitHub cursor-memory-bank — простой memory bank для Cursor IDE. Идея элементарная: агент запоминает контекст проекта между сессиями. Структура, стек, архитектурные решения. Никакой магии, просто markdown-файлы, которые подгружаются в начале разговора.
Мне идея понравилась, но хотелось большего. Я форкнул проект и сделал cursor-memory-bank-angry. "Angry", потому что Angry Robot Deals, моя компания. Добавил команды для управления рабочим процессом. Ввёл TDD как обязательное требование. Создал бэклог. Прикрутил SDLC-фреймворк с декомпозицией задач и автоматическим выбором технологического стека.
Это уже работало лучше, но оставалось привязано к Cursor и к разработке кода. Я хотел систему, которая ведёт любой проект. Исследование. Статью. Юридический документ. DevOps-инфраструктуру. SEO-аудит.
Так появился Datarim v1.3.0 — полноценная платформа. 15 агентов, 18 скиллов, 19 команд, 5 шаблонов, 9-стадийный pipeline. Построен для Claude Code, но архитектура не привязана к конкретному провайдеру.
Ссылки, если хотите проследить эволюцию:
- Оригинал: https://github.com/vanzan01/cursor-memory-bank
- Промежуточная: https://github.com/Angry-Robot-Deals/cursor-memory-bank-angry
- Datarim: https://github.com/Arcanada-one/datarim
Как это работает
Pipeline из 9 стадий:
init → prd → plan → design → do → qa → compliance → reflect → archiveНо не каждая задача проходит все 9. Это было бы безумием — гонять баг-фикс через архитектурный дизайн. Поэтому есть маршрутизация по сложности:
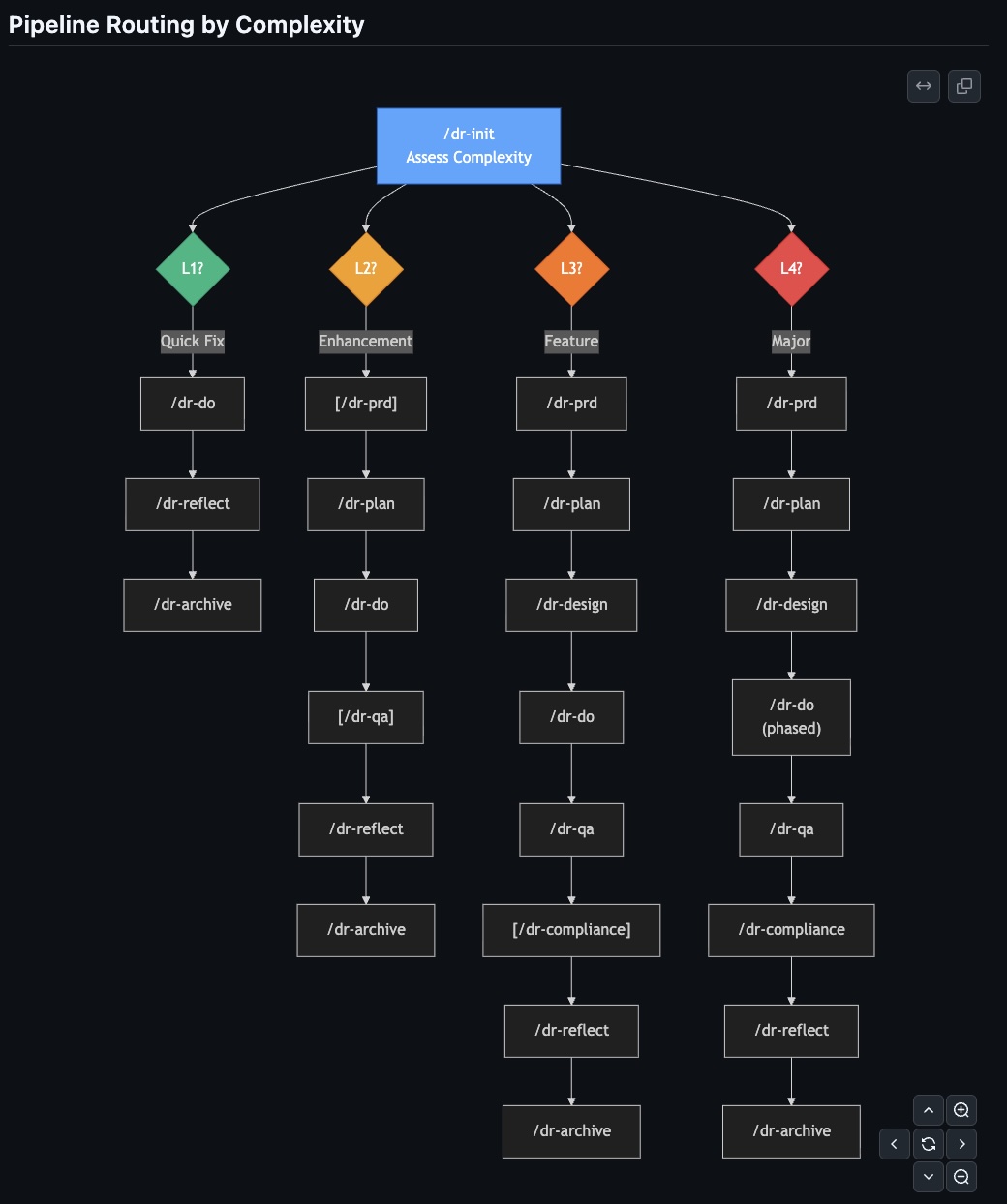
| Уровень | Что это | Pipeline |
|---|---|---|
| L1 Quick Fix | 1 файл, <50 строк | init → do → reflect → archive |
| L2 Enhancement | 2-5 файлов, <200 строк | init → [prd] → plan → do → [qa] → reflect → archive |
| L3 Feature | 5-15 файлов, 200-1000 строк | init → prd → plan → design → do → qa → [compliance] → reflect → archive |
| L4 Major Feature | 15+ файлов, >1000 строк | init → prd → plan → design → phased-do → qa → compliance → reflect → archive |
Скобки — необязательные стадии на этом уровне. L1 задача закрывается за 4 шага. L4 проходит все 9.
15 агентов
Каждый агент — специализированная роль. Не один и тот же Claude в разных шляпах, а разный набор скиллов, правил и контекста для каждой роли:
| Агент | Роль | Когда работает |
|---|---|---|
| planner | Lead Project Manager | init, plan, archive |
| architect | Chief Architect | prd, design |
| developer | Senior Developer (TDD) | do |
| reviewer | QA & Security Lead | qa, reflect |
| compliance | Compliance Runner | compliance |
| code-simplifier | Code Simplification | compliance |
| strategist | Strategic Advisor | plan (L3-4) |
| devops | DevOps Engineer | plan, do, compliance |
| writer | Content Writer | write, reflect, archive, prd |
| editor | Content Editor | edit, qa (content) |
| skill-creator | Skill/Agent/Command Creator | addskill |
| optimizer | Framework Optimizer | optimize, reflect |
| librarian | Knowledge Base Librarian | dream |
| security | Security Analyst | design, qa, compliance |
| sre | Site Reliability Engineer | design, qa, reflect |
Не все агенты нужны на каждой задаче. L1-фикс загружает developer и, может быть, reviewer. L4-проект подтягивает planner, architect, developer, reviewer, strategist и кого ещё потребуется.
18 скиллов
Скиллы — это знания. Не код, а правила и паттерны, которые агент загружает по необходимости:
- datarim-system — ядро, всегда загружен
- ai-quality — TDD, декомпозиция, управление когнитивной нагрузкой
- compliance — 7-шаговый hardening workflow
- security — аутентификация, валидация, защита данных
- testing — пирамида тестирования, правила моков
- performance — паттерны оптимизации
- tech-stack — выбор стека по типу проекта
- utilities — shell-рецепты для типовых операций
- consilium — мульти-агентные панельные обсуждения
- discovery — интервью для сбора требований
- evolution — правила самообновления фреймворка
- writing — создание контента, редакционный workflow
- dream — правила обслуживания базы знаний
- seo-launch — SEO, аналитика, чеклисты запуска
- marketing — рекламные кампании, конверсии, лендинги
- factcheck — проверка фактов в публикациях
- humanize — удаление AI-паттернов из текста
- visual-maps — Mermaid-диаграммы workflow
Как выглядит автономная работа
Представьте: в бэклоге лежит задача BACKLOG-0042 "Добавить JWT-аутентификацию в API". Агент берёт её:
/dr-init— загружает задачу, оценивает сложность как L3/dr-prd— architect формулирует требования: формат токена, expiration, refresh flow, защищённые роуты/dr-plan— planner + strategist разбивают на фазы: middleware, token service, login endpoint, тесты/dr-design— consilium: architect + security обсуждают JWT vs session tokens, принимают решение/dr-do— developer пишет код через TDD: сначала тесты, потом реализация, один метод за итерацию/dr-qa— reviewer проверяет: соответствие PRD, security review, покрытие тестами, OWASP/dr-reflect— reviewer анализирует: "refresh token rotation был недооценён на этапе планирования"/dr-archive— planner архивирует задачу, обновляет бэклог, берёт следующую
Весь цикл. Без моего участия в каждом шаге. Я задаю направление и проверяю результаты.
Фреймворк, который думает о себе
Pipeline можно написать за день. Три механизма, которых я не видел ни в одном другом фреймворке, нет.
Рефлексия
/dr-reflect запускается после каждой задачи. Reviewer-агент анализирует, что пошло хорошо, что плохо, и предлагает конкретные улучшения. Не абстрактное "надо лучше планировать", а "скилл security.md не покрывает rate limiting, добавить секцию". Или "агент developer тратит много токенов на повторное чтение файлов, добавить правило кеширования в ai-quality.md".
Предложения записываются. Человек одобряет или отклоняет. Фреймворк обновляется. Следующая задача выполняется лучше.
За год Datarim прошёл десятки таких циклов. Скиллы, которые существуют сейчас, не были запланированы изначально. factcheck появился после того, как я опубликовал статью с неточными цифрами. humanize — после того, как пост в LinkedIn читался как типичный ChatGPT-выхлоп. seo-launch — после ручного запуска третьего сайта подряд.
Dream
/dr-dream — это библиотекарь. Агент, который не пишет код и не создаёт контент. Он наводит порядок в базе знаний проекта: директории datarim/, все файлы состояния, архивы, рефлексии.
- Ищет противоречия между документами (techContext.md говорит "Express", а code использует Fastify)
- Строит перекрёстные ссылки
- Выбрасывает устаревшую информацию
- Организует файлы, попавшие не в ту директорию
- Обновляет индексы
Я запускаю его раз в неделю-две. После большого спринта или перед началом новой фазы проекта. Чистая база знаний = меньше галлюцинаций агента.
Optimize
/dr-optimize — аудит самого фреймворка. Optimizer-агент проверяет все 18 скиллов, 15 агентов, 19 команд. Ищет:
- Неиспользуемые скиллы (загружаются, но правила из них не применяются)
- Дубликаты (два скилла описывают одно и то же разными словами)
- Сломанные ссылки между файлами
- Рассинхрон между документацией и реальностью
Когда фреймворк растёт органически через рефлексию, накапливается энтропия. Optimize борется с этим.
Consilium
Для критических решений (L3-L4) Datarim собирает панель из нескольких агентов. Architect предлагает архитектуру, Security ищет дыры, DevOps считает операционные затраты, SRE думает о надёжности. Они спорят. В итоге — взвешенное решение.
Это не синтетическая мудрость толпы. Каждый агент загружает свой набор скиллов и видит задачу через свою линзу. Architect оптимизирует под масштабируемость, Security — под безопасность, SRE — под наблюдаемость. Противоречия между ними — это и есть ценность.
С чем путают Datarim
Три заблуждения, на которые натыкаются чаще всего.
Memory layer (mem0.ai)
Datarim — это не mem0.ai и не аналоги. Mem0 решает другую задачу: персистентная память агента. Кто ты, что любишь, какие решения принимал раньше. Это полезно, но это другой слой.
Datarim — структура выполнения проекта. Что делать. В каком порядке. С какой проверкой качества на каждом шаге. Как учиться на результатах. Mem0 помнит, что ты любишь TypeScript. Datarim следит, чтобы ты написал тесты до кода, провёл ревью, задокументировал решения и обновил бэклог.
Разные слои. Совместимы. Можно использовать оба.
Оркестратор агентов (AutoGPT, CrewAI)
Datarim — не оркестратор множества агентов, работающих параллельно. Здесь нет сложной маршрутизации сообщений между агентами в реальном времени. Один агент на стадию. Чёткий pipeline. Следующий агент получает результат предыдущего через файлы в datarim/.
Это проще, чем CrewAI. И надёжнее. Мультиагентные системы с параллельным выполнением красиво выглядят на диаграммах, но в реальности порождают трудно отлаживаемые проблемы координации. Datarim выбирает последовательность и предсказуемость.
Инструмент только для кода
Это, пожалуй, самое частое заблуждение. Да, Datarim вырос из разработки ПО. Но pipeline — требования → план → выполнение → проверка → рефлексия — универсален.
Реальные use cases из документации:
- Юридические документы (SaaS Terms of Service)
- Научные исследования (литобзор, методология)
- Техническая документация (API-доки, архитектурные решения)
- Управление проектами (бэклог, итерации, ретроспективы)
- Контент (статьи, посты, с фактчекингом)
- DevOps (CI/CD, Docker, деплоймент)
- SRE (наблюдаемость, SLO, инцидент-респонс)
- SEO (аудит, аналитика, Search Console)
- Рекламные кампании (Google Ads, структура, трекинг)
- Публикация в App Store (метаданные, скриншоты, privacy policy)
- Запуск сайтов (pre-launch чеклист, SSL, OG-теги)
- UI/UX (лендинги, компоненты, адаптивность)
Эта статья, которую вы сейчас читаете, написана через Datarim. Задача CONTENT-0001. Pipeline: init → plan → write → edit → archive.
Для кого это
Datarim хорошо работает, если вы:
- Solo-разработчик, который хочет выжать максимум из Claude Code
- Стартап, где один-два человека делают работу за десять
- Исследователь, который ведёт масштабный проект с множеством задач
- Контент-команда, которой нужен редакционный процесс с фактчекингом
- Кто угодно, кто работает с AI-агентами и устал от хаотичного freestyle
Datarim не нужен, если вы:
- Не используете AI-агентов (фреймворк без агента — это просто markdown-файлы)
- Пишете одноразовые скрипты (overhead не оправдан)
Если у вас уже есть Jira, Asana, CI/CD и code review — отлично. Datarim не заменяет ваш SDLC, он работает внутри него. Я сам беру задачу из Asana, запускаю /dr-init, и агент ведёт её по pipeline. Бэклог проекта живёт в трекере, бэклог конкретной задачи — в Datarim. Разные уровни.
Отдельно про модели. Datarim построен с учётом ограниченного контекста. На каждом этапе агент загружает минимум необходимой информации: только нужный скилл, только состояние текущей задачи, только файлы, указанные в плане. Не весь проект целиком. Это значит, что фреймворк работает и на моделях с небольшим окном контекста. Не идеально, но работает.
Быстрый старт
Пять минут от нуля до первой задачи.
git clone https://github.com/Arcanada-one/datarim.git
cd datarim && ./install.shСкрипт расставит агентов, скиллы и команды по нужным директориям. Потом:
cp CLAUDE.md /path/to/your/project/
cd /path/to/your/project/
claudeВ Claude Code:
/dr-help # Все команды с описаниями
/dr-init <задача> # Начать работуПервая задача для новичка: попробуйте L1. Опишите простой баг-фикс или маленькое улучшение. /dr-init "Исправить опечатку в README". Агент оценит L1, выполнит init → do → reflect → archive. Вы увидите весь цикл за 5 минут. Потом попробуйте L2 — с планом. Потом L3 — с дизайном и consilium.
Лицензия MIT. Форкайте, адаптируйте, контрибьютьте.
GitHub: https://github.com/Arcanada-one/datarim
Что дальше
Я не буду говорить "будущее выглядит ярко". Скажу конкретно.
Datarim — это фреймворк, который я использую каждый день для реальной работы. Тысяча задач за год — это не маркетинговая цифра, это мой бэклог-архив. Каждая задача оставила рефлексию, и каждая рефлексия сделала фреймворк чуть лучше.
Если вы работаете с AI-агентами и чувствуете, что freestyle-подход упирается в потолок — попробуйте. Клонируйте, запустите /dr-init, закройте пару задач. Если не зайдёт — потратите полчаса. Если зайдёт — сэкономите сотни часов.
Репозиторий открыт. Контрибьюторы приветствуются. Issues — тоже.