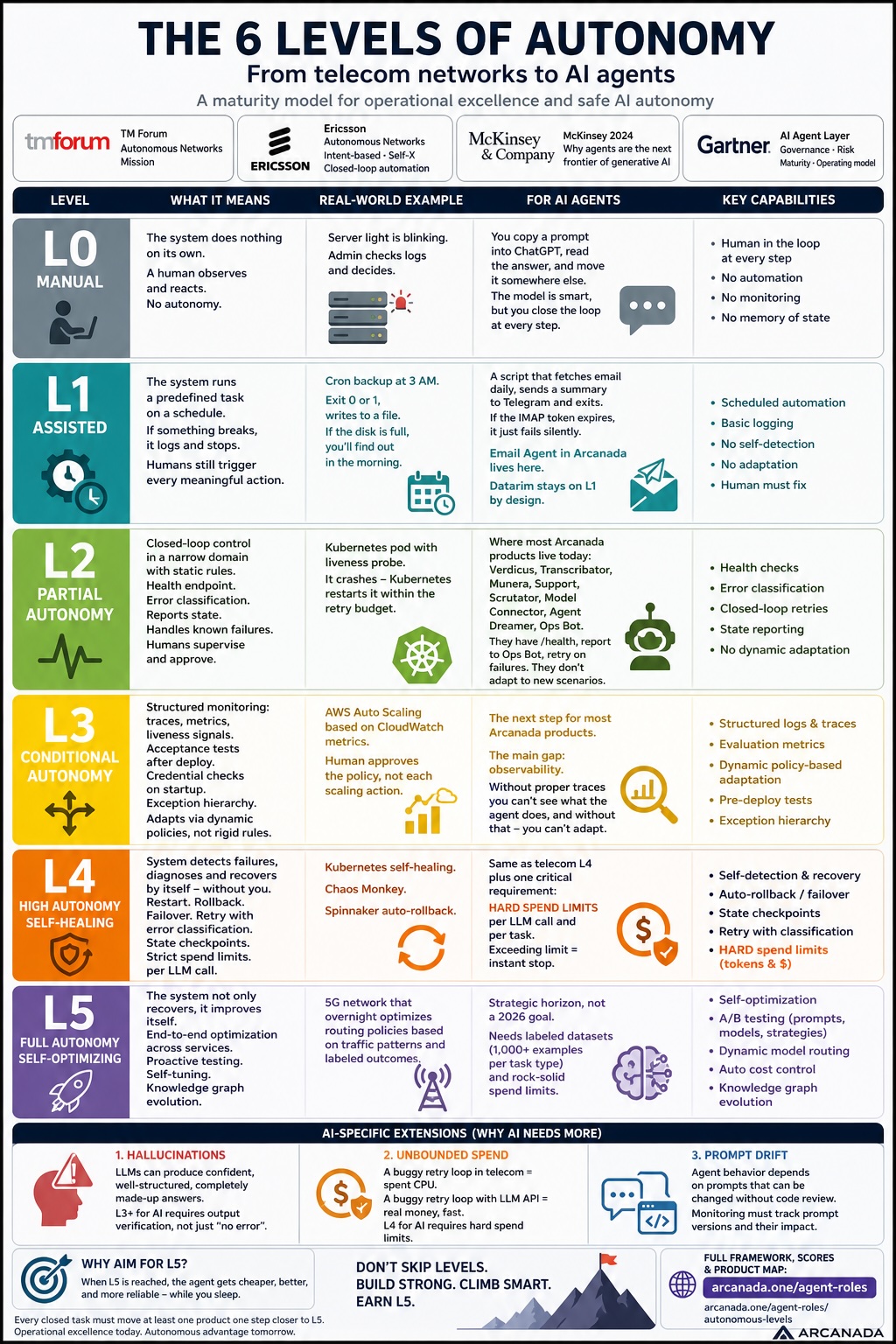
I read a post by Kirill Simakov on autonomy levels for agent systems. The framing was useful, the levels intuitive. The post had no references, so I went looking for the source.
The trail converged on three places. The canonical scale belongs to TM Forum’s Autonomous Networks Mission — six levels (L0–L5) that the telecom industry uses to track operational maturity. Ericsson’s working notes describe how an operator actually climbs the scale: agentic closed-loop automation, intent-driven interactivity, self-X domain capabilities. McKinsey’s 2024 report on agentic systems (“Why agents are the next frontier of generative AI”) reframes the same maturity question for AI: the move from knowledge to action, from chatbots to virtual coworkers that can plan, use tools, collaborate. Gartner’s “AI Agent Layer” brings it back to operational reality — without governance and a maturity model, agent deployments fragment and produce regulatory and reputational damage.
Different vocabularies, same architecture. Telecom built a maturity scale because the cost of an outage is enormous. Agentic AI is now hitting the same operational pressure: hallucinations, runaway loops, prompt drift, and the very real risk of large bills before sunrise.
I took the TM Forum scale, added the AI-specific dimensions that the McKinsey and Gartner pieces flag, applied it to every product in the Arcanada ecosystem, and gave each one an honest rating. Where it actually is right now. The ratings are public — arcanada.ai/agent-roles. From here on, every closed task should move at least one product one notch closer to L5.
What the Six Levels Actually Mean
I’ll walk through them with everyday examples first, then circle back to AI agents.
L0 — Manual
The system does nothing automatically. A human watches and acts. A blinking light on a server. The admin reads logs and reacts. No autonomy.
For an AI agent, this is: you copy a prompt into ChatGPT, read the answer, paste it somewhere else. The model is smart, but the loop is closed by you, every step.
L1 — Assisted
The system runs a pre-configured task on a schedule. If something fails, it writes to a log and stops. The human still drives every meaningful action.
Real-world: a backup cron. Runs at 3 AM, exits 0 or 1, writes to a file. If the disk is full, the cron fails — and you find out the next morning when you check.
For agents: a script that pulls your inbox once a day, sends a summary to Telegram, and exits. Useful, but if the IMAP token expires, the script just fails silently. The Email Agent in Arcanada lives here. Datarim itself is L1 by design — the framework is human-driven on purpose, with the operator approving every transition. L1 is sometimes the target, not a gap.
L2 — Partial Autonomy
Closed-loop operations within a narrow domain, on static rules. The system has a health endpoint. It classifies its errors. It reports its status to a dashboard. The human supervises and approves; the system handles known failure modes.
Real-world: a Kubernetes pod with a liveness probe. It dies, Kubernetes restarts it within a fixed retry budget. No magic, no learning — just a known rule and a closed loop.
For agents: most of the live Arcanada ecosystem sits here. Verdicus, Transcribator, Munera, Support, Scrutator, Model Connector, Agent Dreamer, Ops Bot. They have a /health endpoint. They report to Ops Bot. They retry on failure. But they don’t adapt — if a new failure mode shows up, a human teaches them about it.
L3 — Conditional Autonomy
Now things get interesting. The system has structured observability — traces, evaluation scores, heartbeats. It runs a smoke test after every deploy. It validates its credentials at startup. It has an explicit error hierarchy. And, crucially, it adapts: it changes its behavior based on dynamic policies, not static rules.
Real-world: AWS Auto Scaling driven by CloudWatch metrics. A load metric crosses a threshold, the system scales out. The human approves the policy, not each scaling event.
For agents, L3 is where most of my products are heading. The gap is observability. Without proper traces you can’t see what your agent is doing, and without that you can’t adapt.
L4 — High Autonomy · Self-Healing
The system detects its own failures, diagnoses the root cause, and recovers — without you. Restart the failed container. Roll back to the last known-good version. Failover to a backup provider. Retry with classification (transient vs permanent vs auth). State checkpointing so a multi-step job can resume after a crash. Hard cost circuit breakers for every LLM call.
Real-world: Kubernetes self-healing (pod crashes, gets rescheduled), Netflix Chaos Monkey (deliberately breaking things in production to verify the system recovers), Spinnaker auto-rollback (a deploy fails health checks, the previous version comes back automatically).
For AI agents, L4 has one extra requirement that the telecom version doesn’t emphasize: hard cost limits on every LLM call. There are documented stories of agents running up several-hundred-dollar API bills in hours through a single retry loop. Without a hard cost ceiling, an autonomous agent can drain a budget while looking healthy. So L4 for AI agents is L4 for telecom plus this: every LLM call has a token ceiling, every job has a dollar ceiling, and breaching it triggers an immediate stop.
L5 — Full Autonomy · Self-Optimization
The system doesn’t just fix itself. It improves itself. Closed-loop across multiple services. Proactive A/B testing of prompts and models. Dynamic model routing — cheap model for easy tasks, expensive for hard ones, decided automatically. Cost governance with auto-downgrade for low-priority work. Eval-driven prompt refinement based on observed outcomes. Knowledge-graph evolution — the agent decides which memory nodes to keep, merge, or drop.
Real-world example, telecom: a 5G network that retunes its own routing policies overnight based on observed traffic patterns and a labeled dataset of customer-experience outcomes.
For AI agents, L5 is the strategic horizon, not a 2026 deliverable. It needs two things that are hard to get: a labeled evaluation dataset (1000+ samples per task type, with ground truth) and rock-solid hard cost limits. Without both, L5 is a path to bankruptcy.
Why the Telecom Standard Translates So Well
Telecom networks have spent decades dealing with the exact problems agentic AI is now hitting: anomaly detection, root-cause analysis, automated recovery, graceful degradation across many services that depend on each other. They built rigorous frameworks because the cost of getting it wrong is enormous — a network outage isn’t a customer being annoyed, it’s an emergency call that doesn’t connect. Ericsson’s materials describe this in operational terms: self-X capabilities, intent-driven loops, agentic closed-loop automation across domains.
AI agents inherit those problems and add new ones. Three in particular, all flagged in the McKinsey and Gartner pieces:
- Hallucinations. An LLM can produce a confident, well-structured, completely fabricated answer. Telecom systems don’t have this failure mode. AI agents do. So L3+ for AI needs output validation by schema, not just by absence of an exception.
- Cost runaway. A buggy retry loop in telecom costs CPU. A buggy retry loop with an LLM API costs money. Real money, fast. So L4 for AI requires cost circuit breakers as a first-class capability.
- Prompt drift. Agent behavior depends on a prompt that can change without code review. Observability for AI has to track not just code versions, but prompt versions, and detect when a prompt change degrades the eval score.
The telecom scale is a strong baseline. AI just adds three dimensions on top.
The Hard Part: Climbing the Levels
Reading the levels takes ten minutes. Climbing them takes years.
The hardest jump in my experience is L2 → L3. At L2, you have a health endpoint and you know your service is up. At L3, you need structured logs, traces, eval metrics — a full observability stack. That stack costs money to run (Loki, Grafana, Tempo, eval pipelines), and it costs even more time to wire up correctly. Most teams stall here. They have monitoring but it’s grep-only, and the moment something subtle breaks, no one notices for a day.
The other hard jump is L3 → L4. At L3, the system tells you what went wrong. At L4, it fixes it. Self-healing means you have to enumerate failure modes ahead of time, write recovery logic for each, and trust that recovery enough to let it run without human approval. That trust comes from chaos testing — deliberately breaking things and watching the system recover. Most teams don’t chaos-test, so they never reach real L4.
One small operational scar taught me this. The Email Agent in Arcanada had a broad except: in the IMAP loop that swallowed PermissionError. The agent ran fine, exited 0, wrote a summary — and silently dropped 54 emails over a week. No alert, no log, no clue. The fix was a structured exception hierarchy: every exception class has an explicit handler, no broad catches. That single change moved the agent from “runs without errors” to “fails loudly when it should.” It’s the kind of change that separates L1 from L2 and lets you reach for L3.
Why L5 Is Worth Aiming For
When L5 lands, the agent doesn’t just survive failures. It gets cheaper and better while you sleep.
- An L5 transcription service routes the easy 5-minute clips to a cheap model and the hard hour-long meetings to a premium one — automatically, based on observed quality and cost.
- An L5 model connector A/B-tests new model versions on a small slice of traffic, measures eval scores, and promotes the better model without anyone clicking a button.
- An L5 memory layer notices that two memory nodes always co-occur in retrieval, merges them, and reduces token spend on every future query.
None of this requires AGI. It requires labeled evaluation data, hard cost ceilings, and the L0–L4 foundations underneath. The point of the scale is that L5 is the natural consequence of doing L1 through L4 well. Skip a level, and L5 becomes impossible.
What I’m Doing With This
I rated every product in the Arcanada ecosystem on this scale. The ecosystem average is around L1.8 — most things sit at L2, a few at L1. The L2 products are confidently L2 only when they have a /health endpoint, classified errors, and report status to Ops Bot.
The ratings, target levels, and the specific gaps that block each climb, are public: arcanada.ai/agent-roles. The full L0–L5 spec, with examples, is at arcanada.ai/agent-roles/autonomous-levels.
From here on, every task I close should move at least one product one step closer to its target level. Some of those steps are tiny — adding a /health endpoint, structuring an exception hierarchy. Some are large — wiring up a fallback chain across three model providers with circuit breakers per provider. Either way, the scale gives me a coordinate system. I always know where each product is and what the next step looks like.
If you’re building agent systems, I recommend the same exercise. Start with the TM Forum scale. Read the Ericsson materials for the operator perspective, the McKinsey piece for the agentic-AI framing, and the Gartner article for the governance side. Add the AI-specific dimensions. Rate your products honestly. Publish the ratings, even if it’s embarrassing. Then climb.
I wouldn’t have done the digging without Kirill Simakov’s post — the trail led to a body of work that I’ll keep referencing. Sometimes the most useful thing a piece of writing does is send you looking.