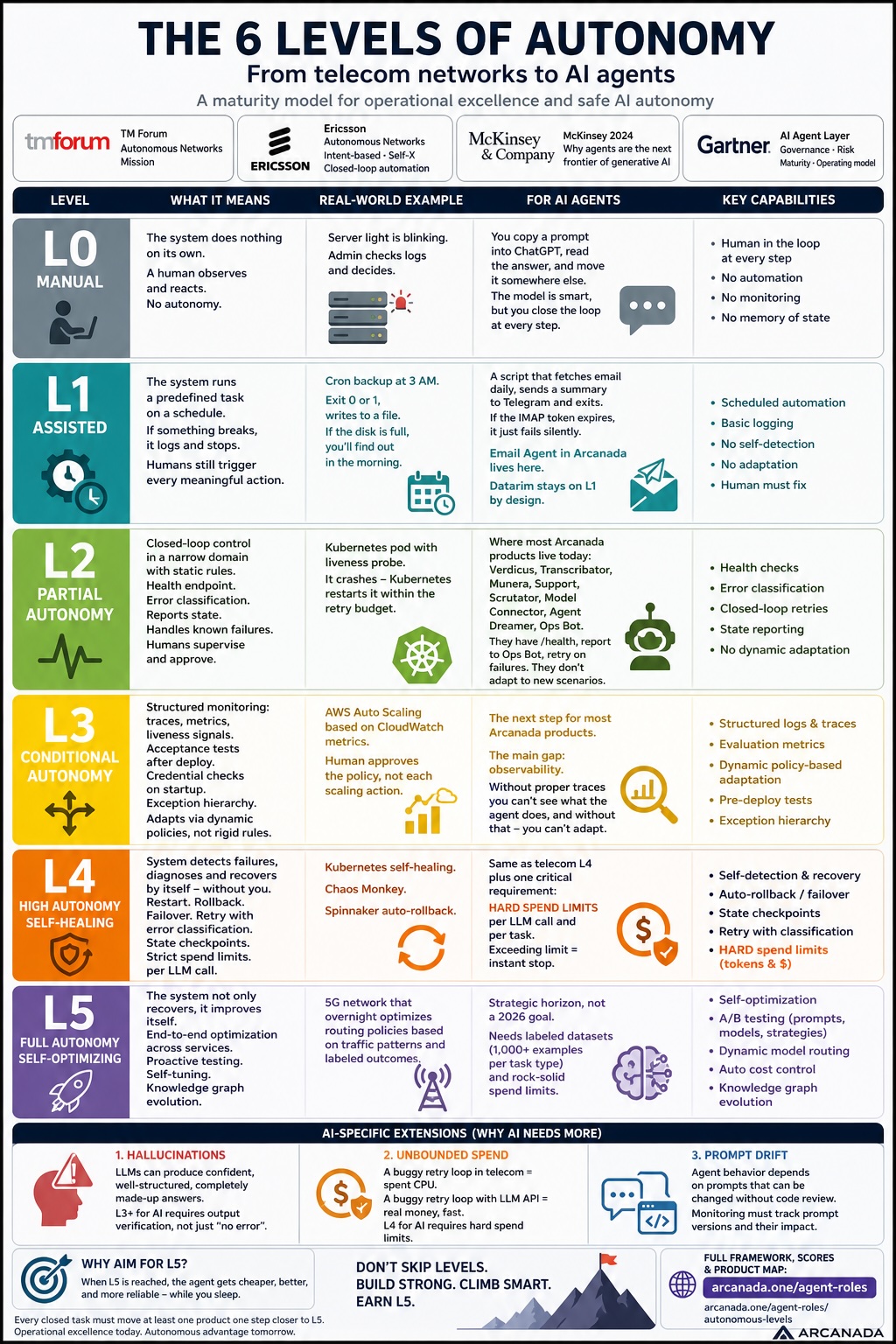
Прочитал пост у Кирилла Симакова про уровни автономности агентных систем. Идея понятная, шкала ясная. В посте не было ссылок на источник, так что я начал искать.
След сошёлся в трёх местах. Каноническая шкала принадлежит TM Forum Autonomous Networks Mission — шесть уровней (L0–L5), которыми телеком-индустрия измеряет операционную зрелость. Рабочие материалы Ericsson описывают, как оператор реально поднимается по этой шкале: агентная замкнутая автоматизация, интент-управление, self-X способности доменов. Доклад McKinsey 2024 года про агентные системы — «Why agents are the next frontier of generative AI» — переформулирует тот же вопрос зрелости для AI: переход от знаний к действию, от чат-ботов к виртуальным коллегам, которые умеют планировать, пользоваться инструментами и сотрудничать. Статья Gartner — «AI Agent Layer» — возвращает разговор в операционную плоскость: без governance и модели зрелости развёртывание агентов фрагментируется и приносит регуляторный и репутационный ущерб.
Разная лексика, та же архитектура. Телеком построил шкалу зрелости, потому что цена сбоя огромная. Агентный AI сейчас попадает под то же операционное давление: галлюцинации, неконтролируемые циклы, дрейф промптов и реальный риск получить большой счёт до восхода солнца.
Я взял шкалу TM Forum, добавил AI-специфичные измерения, на которые указывают McKinsey и Gartner, прошёлся по всем продуктам экосистемы Arcanada и поставил каждому честную оценку. Не желаемую — текущую. Оценки публичные — arcanada.ai/agent-roles. С этого момента каждая закрытая задача должна сдвигать хотя бы один продукт на шаг ближе к L5.
Что значат шесть уровней на самом деле
Пройдусь по ним с бытовыми примерами, потом вернусь к AI-агентам.
L0 — Ручной
Система ничего не делает сама. Человек смотрит и реагирует. Лампочка мигает на сервере, админ читает логи и принимает решение. Никакой автономии.
Для AI-агента это: ты копируешь промпт в ChatGPT, читаешь ответ, переносишь куда-то ещё. Модель умная, но цикл замыкаешь ты, на каждом шаге.
L1 — С поддержкой
Система выполняет заранее настроенную задачу по расписанию. Если что-то падает — пишет в лог и останавливается. Человек по-прежнему запускает каждое значимое действие.
Из жизни: cron бэкапа. Запускается в три часа ночи, exit 0 или 1, пишет в файл. Если диск переполнен, cron упадёт — и ты узнаешь об этом утром, когда сам зайдёшь проверить.
Для агентов: скрипт, который раз в день забирает почту, отправляет сводку в Telegram и завершается. Полезно. Но если IMAP-токен протух, скрипт просто упадёт молча. Email Agent в Arcanada живёт здесь. Datarim сам по дизайну остаётся на L1 — фреймворк намеренно ведётся человеком, оператор одобряет каждый переход. L1 иногда — это цель, а не пробел.
L2 — Частичная автономия
Замкнутый цикл управления в узкой области по статическим правилам. У системы есть эндпойнт здоровья. Она классифицирует свои ошибки. Она отчитывается о состоянии в дашборд. Человек контролирует и одобряет; система сама справляется с известными отказами.
Из жизни: Kubernetes-под с liveness-probe. Упал — Kubernetes перезапустил его в пределах ретрай-бюджета. Никакой магии и никакого обучения — просто известное правило и замкнутый цикл.
Для агентов: здесь живёт большая часть продакшена Arcanada. Verdicus, Transcribator, Munera, Support, Scrutator, Model Connector, Agent Dreamer, Ops Bot. У них есть /health, они отчитываются Ops Bot, делают повторы при падении. Но они не адаптируются — если появится новый сценарий отказа, человек должен научить их вручную.
L3 — Условная автономия
Здесь становится интересно. У системы есть структурированный мониторинг — трассировки, оценочные метрики, сигналы живости. После каждого деплоя она прогоняет приёмочный тест. При старте проверяет учётные данные. У неё явная иерархия исключений. И — главное — она адаптируется: меняет своё поведение по динамическим политикам, а не по жёстким правилам.
Из жизни: AWS Auto Scaling по метрикам CloudWatch. Метрика нагрузки переходит порог — система масштабируется. Человек одобряет политику, а не каждое отдельное масштабирование.
Для агентов L3 — это туда, куда сейчас идёт большинство моих продуктов. Главный пробел — мониторинг. Без нормальных трассировок не видно, что агент вообще делает, а без этого невозможно адаптироваться.
L4 — Высокая автономия · Самовосстановление
Система сама обнаруживает свои отказы, ставит диагноз и восстанавливается — без тебя. Перезапустить упавший контейнер. Откатиться к последней рабочей версии. Переключиться на резервного провайдера. Повторить запрос с классификацией ошибки. Контрольные точки состояния, чтобы многошаговая задача могла продолжиться после падения. Жёсткие лимиты расходов на каждый вызов LLM.
Из жизни: самовосстановление в Kubernetes (под упал — переразвернули), Netflix Chaos Monkey (намеренно ломают сервисы в продакшене, чтобы убедиться, что система восстанавливается), Spinnaker auto-rollback (деплой провалил health-check — предыдущая версия возвращается автоматически).
Для AI-агентов в L4 есть одно дополнительное требование, которое в телеком-версии не подсвечено так остро: жёсткие лимиты расходов на каждый вызов LLM. Есть задокументированные истории, где агенты прокручивали API-счета на несколько сотен долларов за пару часов через один цикл повторов. Без жёсткого потолка по стоимости автономный агент может тихо разорить бюджет, при этом «выглядеть здоровым». Поэтому L4 для AI — это L4 телекома плюс вот это: у каждого вызова LLM есть лимит по токенам, у каждой задачи — лимит по деньгам, превышение — мгновенный стоп.
L5 — Полная автономия · Самооптимизация
Система не просто чинит себя. Она сама себя улучшает. Замкнутый цикл по нескольким сервисам. Проактивное A/B-тестирование промптов и моделей. Динамическая маршрутизация моделей: дешёвая для простых задач, дорогая для сложных, выбор автоматический. Контроль расходов с автопонижением модели для неважных задач. Уточнение промптов на основе наблюдаемых результатов. Эволюция графа знаний — агент сам решает, какие узлы памяти оставить, какие склеить, какие удалить.
Пример из телекома: 5G-сеть, которая ночью перенастраивает свои политики маршрутизации по наблюдаемым потокам трафика и размеченному датасету пользовательских исходов.
Для AI-агентов L5 — это стратегический горизонт, а не цель на 2026 год. Для него нужны две вещи, которые трудно собрать: размеченный датасет для оценки (тысяча и больше примеров на каждый тип задачи, с эталонными ответами) и абсолютно надёжные жёсткие лимиты расходов. Без того и другого L5 — это путь к банкротству.
Почему телеком-стандарт так хорошо ложится
Телеком-сети десятилетиями имели дело ровно с теми проблемами, на которые сейчас наталкивается агентный AI: обнаружение аномалий, разбор причин, автоматическое восстановление, плавная деградация системы из множества зависящих друг от друга сервисов. Они построили строгие фреймворки, потому что цена ошибки очень высокая — отказ сети это не «клиент расстроен», это «вызов скорой не прошёл». Материалы Ericsson описывают это в операционных терминах: self-X способности, интент-петли, агентная замкнутая автоматизация между доменами.
AI-агенты получают эти проблемы по наследству и добавляют свои. Три самые заметные, на которые указывают и McKinsey, и Gartner:
- Галлюцинации. LLM может выдать уверенный, хорошо структурированный, полностью выдуманный ответ. У телеком-сетей такого режима отказа нет, у AI-агентов — есть. Поэтому L3+ для AI требует проверки вывода по схеме, а не только по отсутствию исключения.
- Безудержные расходы. Багованный цикл повторов в телекоме — это потраченный CPU. Багованный цикл повторов с LLM API — это потраченные деньги. Реальные деньги, быстро. Поэтому в L4 для AI жёсткие лимиты расходов — это не приятный бонус, а обязательное требование.
- Дрейф промптов. Поведение агента зависит от промпта, который можно изменить без код-ревью. Мониторинг для AI должен отслеживать не только версии кода, но и версии промптов — и ловить, когда правка промпта роняет оценочную метрику.
Телеком-шкала — это сильная база. AI просто добавляет ещё три измерения сверху.
Самое сложное — это подняться
Прочитать про уровни — десять минут. Подняться по ним — годы.
На моём опыте самый трудный шаг — L2 → L3. На L2 у тебя есть /health, и ты знаешь, что сервис жив. На L3 нужны структурированные логи, трассировки, оценочные метрики — целый стек наблюдаемости. Этот стек стоит денег в эксплуатации (Loki, Grafana, Tempo, пайплайны оценки) и ещё больше — времени на правильную настройку. Большинство команд застревают здесь. У них есть мониторинг, но grep-only — и в момент, когда что-то ломается тонко, никто не замечает сутки.
Второй трудный шаг — L3 → L4. На L3 система сообщает, что пошло не так. На L4 — сама чинит. Самовосстановление означает, что ты должен заранее перечислить сценарии отказа, написать логику восстановления для каждого, и доверить этой логике работать без одобрения человеком. Доверие приходит из хаос-тестов: ты намеренно ломаешь систему и смотришь, как она восстанавливается. Большинство команд хаос-тесты не делают, поэтому до настоящего L4 не доходят.
Один маленький операционный шрам меня этому научил. У Email Agent в Arcanada в IMAP-цикле был широкий except:, который проглатывал PermissionError. Агент работал нормально, выходил с кодом 0, писал сводку — и за неделю тихо потерял 54 письма. Ни алерта, ни лога, ни намёка. Лекарство — структурированная иерархия исключений: у каждого класса исключения свой обработчик, никаких широких ловушек. Один такой переход — и агент перестаёт быть «работает без ошибок» и становится «громко падает, когда должен». Это и есть граница между L1 и L2, и пропуск к L3.
Зачем стремиться к L5
Когда L5 дойдёт, агент не просто переживает падения. Он сам становится дешевле и лучше, пока ты спишь.
- L5 транскрибатор отправляет лёгкие пятиминутные клипы в дешёвую модель, а тяжёлые часовые встречи — в премиальную. Автоматически, на основе наблюдаемого качества и стоимости.
- L5 коннектор моделей сам гоняет A/B-тесты новых версий моделей на небольшом срезе трафика, измеряет оценочные метрики и продвигает лучшую модель без единого клика.
- L5 слой памяти замечает, что два узла всегда вылезают вместе при поиске, склеивает их и снижает расход токенов на каждом будущем запросе.
Ничего из этого не требует AGI. Нужны размеченные данные для оценки, жёсткие лимиты расходов и крепкая основа из L0–L4. Смысл шкалы в том, что L5 — это естественное следствие хорошо сделанных L1–L4. Пропустишь уровень — L5 окажется недостижимым.
Как я это применяю
Я расставил оценки каждому продукту экосистемы Arcanada по этой шкале. Среднее по экосистеме — около L1.8: большинство на L2, несколько на L1. Уверенно на L2 стоят только те продукты, у которых уже есть /health, классифицированные ошибки и отчёт о состоянии в Ops Bot.
Оценки, целевые уровни и конкретные пробелы, которые блокируют каждый подъём, — публичные: arcanada.ai/agent-roles. Полное описание L0–L5 с примерами: arcanada.ai/agent-roles/autonomous-levels.
С этого момента каждая закрытая задача должна сдвигать хотя бы один продукт на шаг ближе к целевому уровню. Часть шагов крошечная — добавить /health, структурировать иерархию исключений. Часть большая — собрать резервную цепочку из трёх провайдеров моделей с предохранителем на каждого. В любом случае шкала даёт мне систему координат: я всегда знаю, где находится каждый продукт и как выглядит следующий шаг.
Если строите агентные системы — рекомендую сделать то же самое. Начните со шкалы TM Forum. Прочитайте материалы Ericsson — там операторская оптика; статью McKinsey — для агентного AI-обрамления; Gartner — для governance-стороны. Добавьте AI-специфичные измерения. Расставьте честные оценки своим продуктам. Опубликуйте, даже если стыдно. И начинайте подниматься.