I’ve been digging through Claude Code’s source code again. This time — not architecture, but something more practical: internet myths vs reality, verified line by line.
The internet is full of “Claude Code hacks.” I took the most popular ones, opened the source, and verified each one. Half don’t work. A quarter work differently than described. And some things actually break functionality.
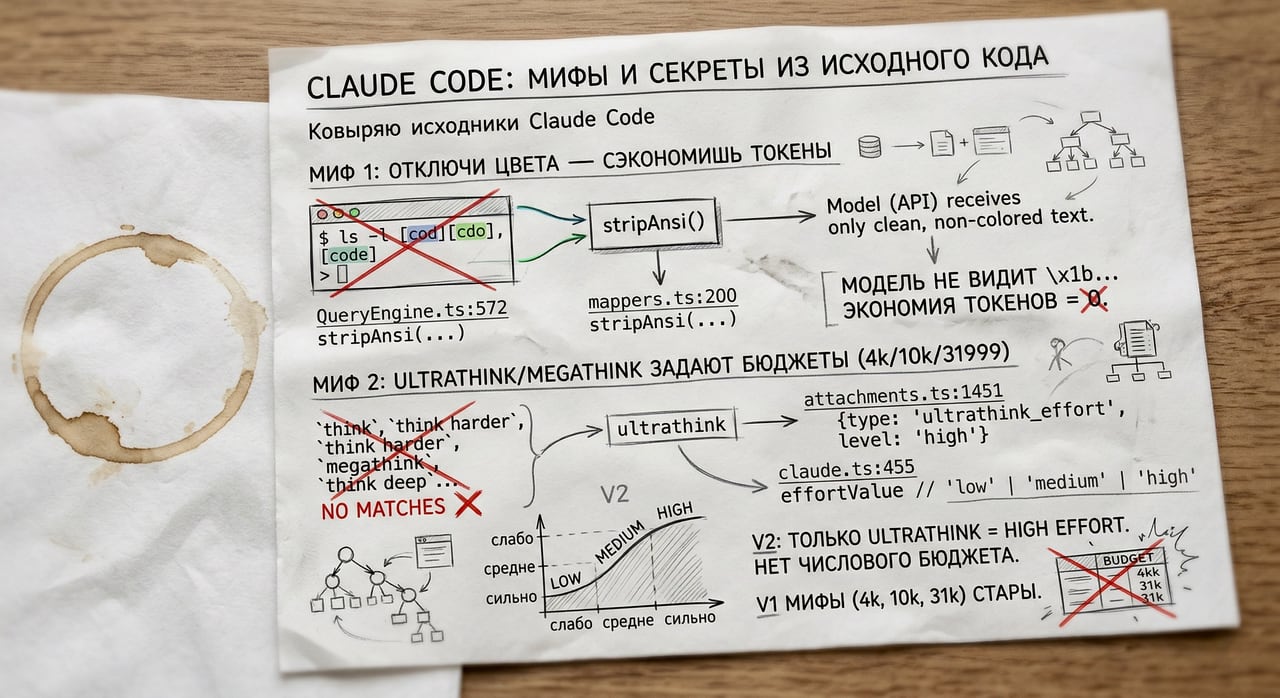
Myth 1: “Disable colors to save tokens”
The advice: set NO_COLOR=1 to prevent ANSI escape codes from eating your context window.
The code (QueryEngine.ts, line 572):
content: stripAnsi(msg.message.content)And mappers.ts, line 200:
const cleanContent = stripAnsi(rawContent)Claude Code already calls stripAnsi() before every API request. The model never sees \x1b[38;2;215;119;87m. Colors are purely a terminal thing. Disabling them costs you readability and saves exactly zero tokens. Zero.
Myth 2: “ultrathink/megathink/think harder set token budgets of 4000/10000/31999”
The most persistent myth. It circulates post to post: “think” = 4,000, “think hard”/“megathink” = 10,000, “ultrathink”/“think harder” = 31,999 thinking tokens. A neat table with three tiers, links to “source analysis.”
The problem: those numbers are from Claude Code v1. In v2, the system was completely redesigned.
I open thinking.ts in the current version. There is exactly one regex:
/\bultrathink\b/i“megathink”? Not in the code. “think harder”? No. “think hard”? No. “think deeply”? No. Grep across all of src/ — zero matches. Of all the “magic words,” only one survived: ultrathink.
What does it do? In attachments.ts, line 1451:
return [{ type: 'ultrathink_effort', level: 'high' }]And in claude.ts, line 455 — effort is passed to the API as a string:
outputConfig.effort = effortValue // 'low' | 'medium' | 'high'No numeric budget. Effort is a string parameter: low, medium, or high. The model decides how to interpret it.
Most importantly — for 4.6 models (Opus, Sonnet), adaptive thinking is used (claude.ts, line 1611):
thinking = { type: 'adaptive' }The model decides how many tokens to spend thinking. The budget_tokens field only applies to older models that don’t support adaptive.
Bottom line: ultrathink is real (restored in v2.1.68), but it’s just an effort toggle: medium → high. The beautiful tables with token budgets are outdated v1 information. “megathink” and “think harder” are invented words the code doesn’t process. And ultrathink only works in the CLI — behind a build-time feature gate and GrowthBook flag.
Myth 3: “DISABLE_TELEMETRY is a safe setting”
Partially true, partially a trap. DISABLE_TELEMETRY=1 does disable Datadog, analytics, and surveys. But there’s a side effect no one writes about.
The chain in the code:
DISABLE_TELEMETRY → isTelemetryDisabled() → isAnalyticsDisabled() → GrowthBook OFFGrowthBook is the feature flags system. When it’s off, all features controlled via feature flags fall back to defaults. This affects effort levels, ultrathink activation, and potentially other A/B tests you’re in.
Good news: 1M context is not affected by GrowthBook. Verified in context.ts and check1mAccess.ts — it’s controlled by subscription and a separate variable CLAUDE_CODE_DISABLE_1M_CONTEXT.
Secret: Two Privacy Levels
In privacyLevel.ts — three modes:
default— everything enabledno-telemetry(DISABLE_TELEMETRY=1) — disables analytics, keeps useful featuresessential-traffic(CLAUDE_CODE_DISABLE_NONESSENTIAL_TRAFFIC=1) — paranoia mode
The second level disables everything non-essential: model capabilities updates, rate limit prefetch, bootstrap config, release notes, MCP registry. This is designed for incident response (when Anthropic servers are overloaded), not everyday use.
The optimal privacy setup — add to .zshrc:
export DISABLE_TELEMETRY=1
export DISABLE_ERROR_REPORTING=1
export DO_NOT_TRACK=1That’s enough. Datadog, analytics, error reporting — all off. And useful features (model capabilities, rate limits, updates) keep working.
Bonus: What Actually Saves Tokens
From what’s confirmed by code:
/clearbetween tasks — every message resends the full context, so a long history is genuinely expensive- Prompt cache lives for 5 minutes (
CACHE_TTL_5MIN_MS = 5 * 60 * 1000inpromptCacheBreakDetection.ts). A pause longer than 5 minutes — cache is dropped, everything is reprocessed from scratch - Auto-compaction triggers 13,000 tokens before the limit (a fixed buffer, not a percentage). For a 200k model that’s ~93.5%, for 1M — ~98.7%
- Every MCP server adds all its tool descriptions to every request. Disconnect unused ones
Methodology: every claim verified against reconstructed source code with file and line number. Nothing taken on faith, everything by the code.