Уже целую неделю я завис на создании Scrutator (поисковый движок) и Long Term Memory для экосистемы Arcanada. Обоим системам нужны сотни LLM-вызовов: извлечение сущностей, переранжирование, классификация. Большие сложности вызывает нестабильное взаимодействие с CLI-моделями по подписке. Да, это условно бесплатно, что хорошо, потому что основная нагрузка в экосистеме будет не на работе самих агентов, а на взаимодействии с базой знаний и управлении ей. CLI-агентов удалось приручить — они будут выполнять основную работу по созданию контента, программного кода, инфраструктурных задач. А с базой знаний придётся работать через провайдеров типа OpenRouter или прямые API вендоров моделей. Это большие затраты, поэтому столько времени на самом старте уходит на исследования и оптимизацию расходов.
Всё это заставило провести нормальный бенчмарк.
Что тестировал
Model Connector — мой unified REST API, который оборачивает 5 коннекторов в один эндпоинт. Три CLI (Cursor, Claude Code, Gemini CLI) — запускают консольные приложения, созданные для интерактивной работы человека. Два API (OpenRouter, self-hosted Embedding) — стандартные HTTP-эндпоинты для серверных нагрузок.
Я отправил 5 логических и математических вопросов 20 моделям и замерил точность, задержку и стоимость. Вопросы намеренно простые: расчёт скорости, задача про овец, головоломка с коробками, факториал, и классическая задача про бейсбольную биту и мяч. Если модель не может решить это — она не готова для работы с базой знаний.
Проблема последовательного выполнения
Это главное открытие всего бенчмарка.
CLI-коннекторы используют файловую аутентификацию — файлы keyring, сессионные токены, OAuth-конфиги на диске. При параллельных вызовах они борются за эти файлы. Cursor'овский cli-config.json ломается при одновременном доступе — пришлось жёстко ограничить параллелизм до 1 после многократных потерь авторизации. Claude Code и Gemini формально поддерживают 4 параллельных вызова, но под нагрузкой теряют авторизацию, упираются в лимиты провайдера и портят сессии.
Это консольные приложения. Они созданы для человека за терминалом, а не для сервера, отправляющего 100 запросов в минуту.
Влияние на пропускную способность:
| Сценарий | CLI (последовательно) | API (параллельно) | Разница |
|---|---|---|---|
| 5 вопросов бенчмарка | 59 секунд | 3 секунды | 20x |
| 100 chunks LTM ingest | ~17 минут | ~1 минута | 17x |
| 50 результатов rerank | ~8 минут | ~30 секунд | 16x |
У API-провайдеров этой проблемы в значительной степени нет. Stateless Bearer-токен, connection pooling, 10–1000+ одновременных запросов. Фундаментально другая архитектура.
Проблема структурированного вывода
Фреймворки для работы с базой знаний (Graphiti, Cognee, LangChain) ожидают json_schema — строгую Pydantic-валидацию ответов LLM. Имена полей должны быть точными. Типы должны совпадать. Это критично для всей экосистемы Arcanada: Scrutator использует структурированный вывод для извлечения сущностей, а Long Term Memory опирается на него при построении графов связей.
Из моих 5 коннекторов только Claude Code CLI и OpenRouter поддерживают native JSON Schema. Cursor и Gemini умеют лишь json_object — вставляют в промпт "ответь в JSON" и надеются на лучшее. LLM часто возвращает корректный JSON, но с неправильными именами полей (entity_nodes вместо extracted_entities), что ломает Pydantic-валидацию.
Я написал прокси с усиленным промптом и перемаппингом полей после ответа, который в основном решает проблему. Но "в основном" недостаточно для пайплайна, обрабатывающего тысячи документов.
Эти два ограничения усиливают друг друга: нет структурированного вывода + нет параллелизма = CLI непригодны для пайплайнов базы знаний. Каждый вызов и медленный, и ненадёжный по формату ответа.
Результаты бенчмарка
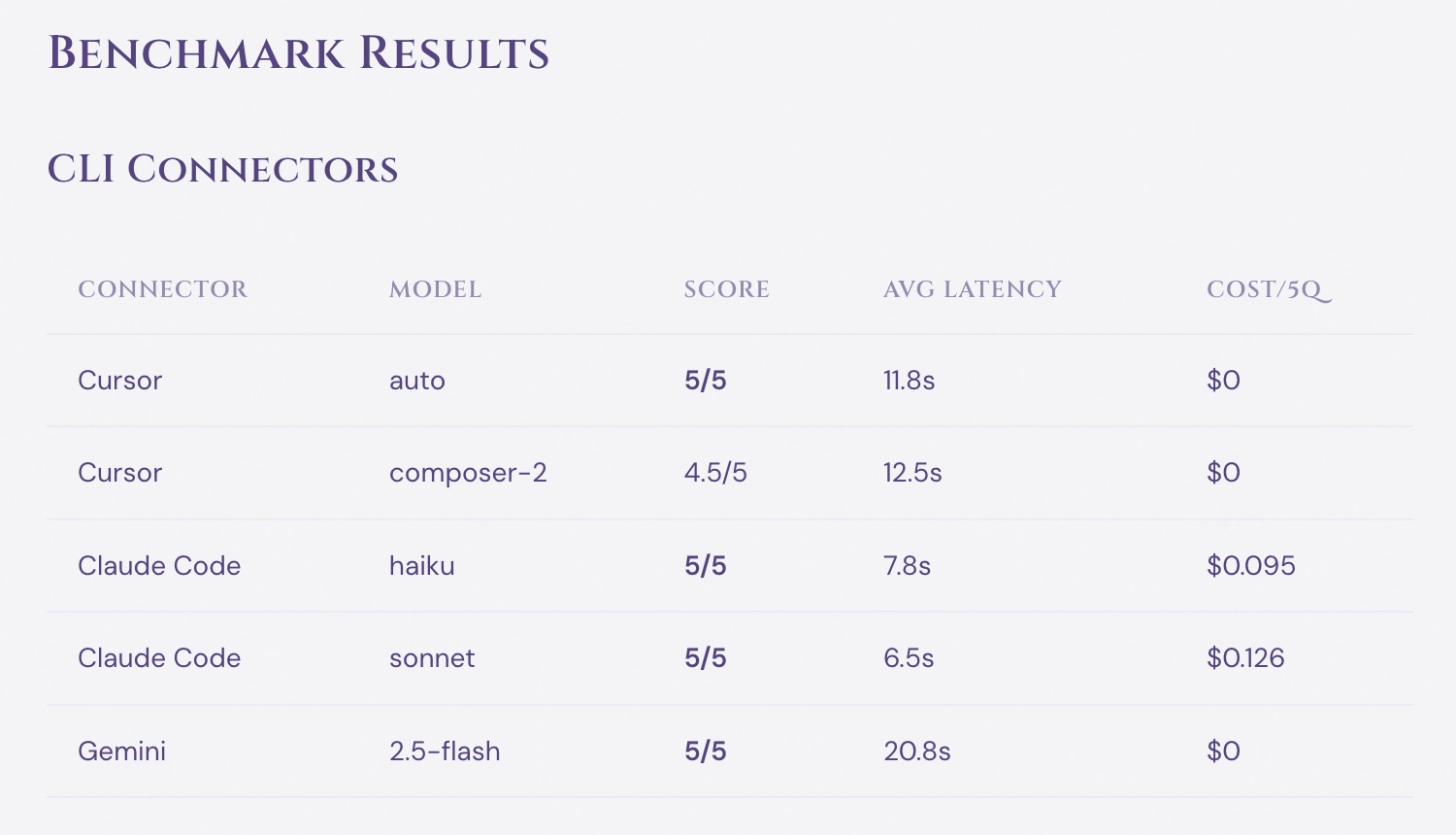
CLI-коннекторы
| Коннектор | Модель | Точность | Ср. задержка | Стоимость/5 вопросов |
|---|---|---|---|---|
| Cursor | auto | 5/5 | 11.8s | $0 |
| Cursor | composer-2 | 4.5/5 | 12.5s | $0 |
| Claude Code | haiku | 5/5 | 7.8s | $0.095 |
| Claude Code | sonnet | 5/5 | 6.5s | $0.126 |
| Gemini | 2.5-flash | 5/5 | 20.8s | $0 |
Все CLI-модели отлично справляются с логическими задачами. Точность не проблема — проблема в пропускной способности.
OpenRouter — бесплатные модели
| Модель | Точность | Ср. задержка | Примечания |
|---|---|---|---|
| NVIDIA Nemotron 120B :free | 5/5 | 14.7s | Лучшая бесплатная модель |
| NVIDIA Nemotron 30B :free | 5/5 | 3.5s | Быстрая и точная — основной выбор |
| OpenAI GPT-OSS 120B :free | 5/5 | 5.5s | Идеальная точность, хорошая скорость |
| NVIDIA Nemotron Nano 9B :free | 5/5 | 36.6s | Самая маленькая модель с идеальной точностью |
| MiniMax M2.5 :free | 4/4* | 25.1s | *Один вопрос не уложился по времени |
| InclusionAI Ling 2.6 :free | 3/5 | 0.9s | Самая быстрая в тесте |
| Z-AI GLM 4.5 Air :free | 4/4** | ~73s | **Медленная, частично ограничена по лимитам |
Четыре бесплатные модели дают идеальную точность 5/5 — три NVIDIA Nemotron и OpenAI GPT-OSS. Nemotron 30B — лучший выбор: быстрая (3.5s), точная, бесплатная.
Я протестировал 25+ бесплатных моделей на OpenRouter. Стабильно отвечают только 7. Остальные — включая Google Gemma, Meta Llama 70B, Qwen3, Nous Hermes 405B — упираются в лимиты на стороне самих провайдеров моделей после 1–2 запросов. Это происходит даже с пополненным балансом: провайдеры сами дросселируют бесплатные эндпоинты в пиковые часы. Около 70% каталога бесплатных моделей на OpenRouter ненадёжны для пакетных нагрузок.
OpenRouter — дешёвые платные модели
| Модель | Точность | Ср. задержка | Стоимость/5 вопросов |
|---|---|---|---|
| Qwen 3.5 9B | 5/5 | 33.5s | $0.003 |
| Seed 2.0 Mini | 5/5 | 26.4s | $0.002 |
| Step 3.5 Flash | 4/4* | 15.1s | $0.001 |
| GLM 4.7 Flash | 4/5 | 16.6s | $0.002 |
| Kimi K2.6 | 3/5 | 43.7s | $0.015 |
Qwen и Seed дают идеальную точность менее чем за полцента на 5 вопросов. При такой цене 1000 LLM-вызовов стоят около 60 центов.
Как устроен биллинг CLI-подписок
CLI-модели не совсем бесплатные — оплата идёт через подписку:
- Cursor Pro ($20/мес) — кредитная система: подписка включает $20 credit pool. В Auto-режиме кредиты расходуются экономно, ручной выбор premium-моделей (Claude Sonnet, GPT-4o) тратит пул быстрее. Стоимость запроса не сообщается.
- Claude Code Max ($100/мес) — фиксированная подписка с бюджетом токенов, который обновляется каждые 5 часов. Каждый запрос сообщает точную стоимость: haiku $0.01–0.04, sonnet $0.02–0.03 за вызов. Единственный CLI с поддержкой JSON Schema.
- Gemini CLI (бесплатно) — бесплатно через личный Google-аккаунт с лицензией Gemini Code Assist: 60 запросов в минуту, 1000 в день. Без трекинга стоимости, без JSON Schema, самый медленный — 20+ секунд в среднем.
Для агентских задач (генерация кода, написание контента, инфраструктура), где 5–20 вызовов за сессию, подписка работает отлично. Модели высокого качества при нулевой дополнительной стоимости.
Для пайплайнов базы знаний с 100–1000 вызовами за пакет последовательное выполнение убивает любой выигрыш от бесплатности.
Инфраструктурные находки
Бенчмарк был не только про качество моделей. Прогон 20 моделей через продакшн API вскрыл реальные инфраструктурные проблемы, которые потом ударили бы по пайплайнам LTM и Scrutator.
Таймаут Cloudflare-прокси
Cloudflare обрывает соединение после ~100 секунд. Thinking-модели вроде Step 3.5 Flash думают по 4+ минуты — соединение молча рвётся, клиент получает пустую ошибку 524 без полезной диагностики. Во время бенчмарка я потерял несколько результатов, прежде чем разобрался, что происходит. Решение: обойти Cloudflare и вызывать Model Connector напрямую через Tailscale. Для продакшна это значит, что любой пайплайн с thinking-моделями должен идти мимо CDN.
Каскадный сбой circuit breaker
В Model Connector есть circuit breaker для защиты от падающих провайдеров — после 5 ошибок подряд он перестаёт отправлять запросы на 30 секунд. Проблема: он работает по коннектору (OpenRouter), а не по модели. Когда бесплатная модель вроде Google Gemma упирается в лимит провайдера, circuit breaker открывается и блокирует ВСЕ запросы через OpenRouter — включая платные модели, которые работают нормально. Во время тестирования одна заблокированная бесплатная модель выбивала весь мой OpenRouter-пайплайн на 30 секунд за раз. Для инжеста базы знаний, обрабатывающего сотни документов, такой мелкий rate limit превращается в полную остановку пайплайна. Нужно переделать на по-модельный circuit breaker.
Путаница контекстов Kimi K2.6
Kimi K2.6 отвечал на Q5 ответом от Q4, а на Q2 — ответом от Q1. При том что каждый запрос полностью независимый (отдельные HTTP-вызовы, никакого общего контекста). Модель, похоже, сохраняет фантомный контекст из своей внутренней цепочки рассуждений между запросами. Это баг на стороне модели, который я не могу исправить, но знать о нём стоит: Kimi ненадёжен для любой нагрузки, где важна изоляция ответов.
Итог
Для Long Term Memory и Agent Dreamer я буду использовать платные модели OpenRouter — наименее дорогие, но качественные. При $0.002–0.003 за 5 запросов это доли цента за каждую операцию с базой знаний, и при этом есть параллельное выполнение и строгая поддержка JSON Schema.
Для разработки, создания контента и инфраструктурных задач CLI-коннекторы по подписке остаются правильным выбором. Агенты приручены, точность 100%, дополнительных затрат ноль.
Один API, два паттерна трафика, ноль лишних расходов.
Model Connector — проект с открытым кодом: github.com/Arcanada-one/model-connector.